- Published on
Dify 中使用 MCP 协议访问 ClickHouse 搭建完整教程
- Authors

- Name
- Shoukai Huang

在本教程中,我将详细介绍如何在 Dify 平台中通过 MCP 协议连接 ClickHouse 数据库,实现数据分析和可视化功能。这个集成方案可以帮助开发者在 AI 应用中轻松访问和分析大规模数据,提升 LLM 应用的数据处理能力。
目录
1. Dify 介绍
Dify 官方手册 介绍如下
Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上。
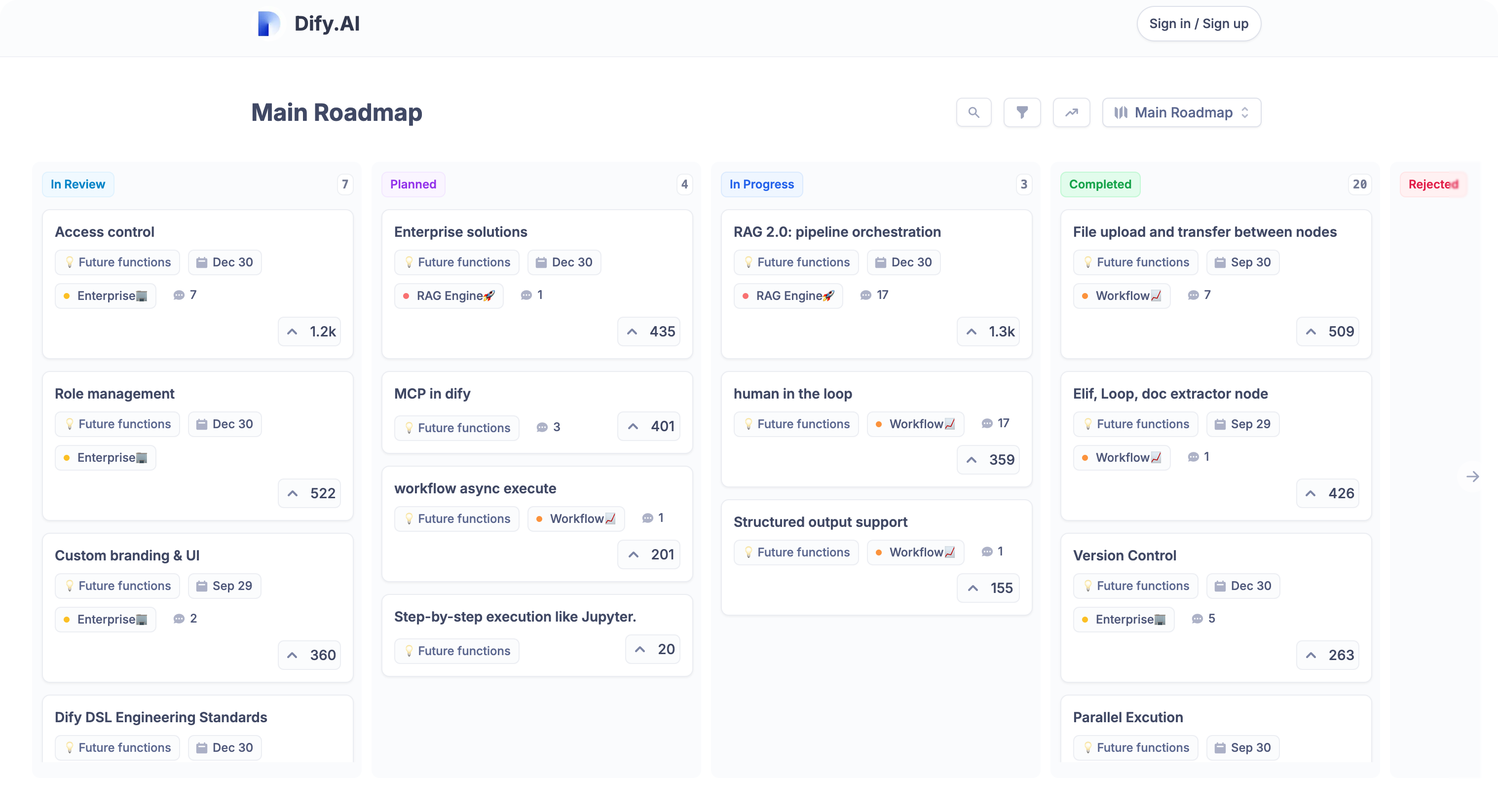
1.1 Dify 产品路线图
Main Roadmap ,内容来源:https://roadmap.dify.ai/roadmap
1.2 开源协议
Dify 的社区版本是开源的,采用基于 Apache 2.0 的开源许可,并附加额外条件。协议原文
# Open Source License
Dify is licensed under a modified version of the Apache License 2.0, with the following additional conditions:
1. Dify may be utilized commercially, including as a backend service for other applications or as an application development platform for enterprises. Should the conditions below be met, a commercial license must be obtained from the producer:
a. Multi-tenant service: Unless explicitly authorized by Dify in writing, you may not use the Dify source code to operate a multi-tenant environment.
- Tenant Definition: Within the context of Dify, one tenant corresponds to one workspace. The workspace provides a separated area for each tenant's data and configurations.
b. LOGO and copyright information: In the process of using Dify's frontend, you may not remove or modify the LOGO or copyright information in the Dify console or applications. This restriction is inapplicable to uses of Dify that do not involve its frontend.
- Frontend Definition: For the purposes of this license, the "frontend" of Dify includes all components located in the `web/` directory when running Dify from the raw source code, or the "web" image when running Dify with Docker.
2. As a contributor, you should agree that:
a. The producer can adjust the open-source agreement to be more strict or relaxed as deemed necessary.
b. Your contributed code may be used for commercial purposes, including but not limited to its cloud business operations.
Apart from the specific conditions mentioned above, all other rights and restrictions follow the Apache License 2.0. Detailed information about the Apache License 2.0 can be found at http://www.apache.org/licenses/LICENSE-2.0.
The interactive design of this product is protected by appearance patent.
© 2025 LangGenius, Inc.
协议限制:多租户、LOGO等内容,其他基于 Apache License 2.0,翻译版本如下:
# 开源许可证
Dify 是根据 Apache License 2.0 的修改版本授权的,并附带以下附加条件:
1. Dify 可用于商业用途,包括作为其他应用程序的后端服务或企业应用程序开发平台。若满足以下条件,则必须从生产商处获得商业许可:
a. 多租户服务:除非获得 Dify 的明确书面授权,否则您不得使用 Dify 源代码来运营多租户环境。
- 租户定义:在Dify环境下,一个租户对应一个工作区,工作区为每个租户的数据和配置提供一个独立的区域。
b.LOGO及版权信息:在使用Dify前端的过程中,您不得删除或修改Dify控制台或应用程序中的LOGO或版权信息。此限制不适用于不涉及Dify前端的使用。
- 前端定义:为了本许可的目的,Dify 的“前端”包括从原始源代码运行 Dify 时位于“web/”目录中的所有组件,或使用 Docker 运行 Dify 时的“web”图像。
请通过电子邮件联系business@dify.ai询问许可事宜。
2. 作为贡献者,您应当同意:
a. 生产者可以根据需要对开源协议进行调整,使其更加严格或者宽松。
b.您贡献的代码可能会被用于商业用途,包括但不限于其云业务运营。
除上述特定条件外,其他所有权利和限制均遵循 Apache License 2.0。有关 Apache License 2.0 的详细信息,请访问 http://www.apache.org/licenses/LICENSE-2.0。
该产品的交互设计受外观专利保护。
© 2025 LangGenius, Inc.
1.3 归属公司
从爱企查获得信息,品牌归属为:苏州语灵人工智能科技有限公司
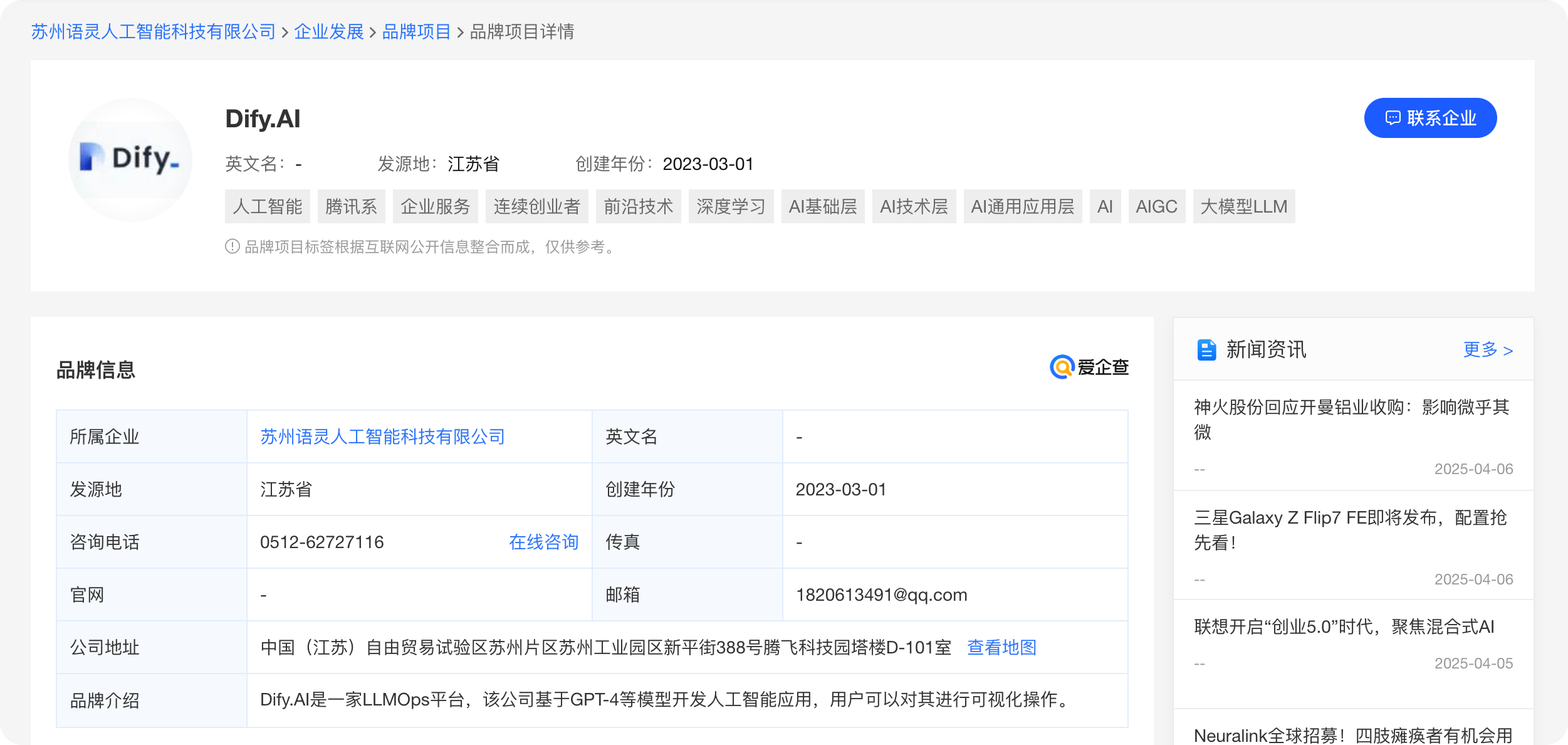
目前公司处于创业期,融资情况(20250406),公司以 Dify 产品为主,后续会有持续的商业资源投入,开源社区无人维护风险较低。

2. Dify 环境配置
2.1 Dify 安装
本文采用 Dify 社区版的 Docker Compose 部署方式。版本演进较快,可能与当前记录方式有差异。以官方手册为准。
Docker Compose 部署: https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/docker-compose
安装 Dify 之前, 请确保你的机器已满足最低安装要求:CPU >= 2 Core & RAM >= 4 GiB
(1)克隆 Dify 源代码至本地环境。
git clone [https://github.com/langgenius/dify.git](https://github.com/langgenius/dify.git) --branch 0.15.3
(2)启动 Dify
cd dify/docker
cp .env.example .env
# 启动 Docker 容器,根据你系统上的 Docker Compose 版本,选择合适的命令来启动容器。
docker-compose up -d
注意:由于 Dify 的 Docker 容器内容较多,如果像本文一样,搭建 RagFlow 后又搭建 Dify,很容易出现冲突情况,需要再 Docker 容器上加上命名空间
docker-compose -p dify up -d
docker-compose -p 命令用于在 Docker Compose 中指定项目的名称,覆盖默认的目录名作为项目名,基本用法
docker-compose -p <项目名称> [其他命令]
例如:# 启动项目并指定名称
docker-compose -p myproject up -d
(3)配置 Dify
如果需要 Dify 启动内容,.env 还需要看一下的,里面可以配置的内容还是比较丰富的。
(4)检查安装
检查是否所有容器都正常运行:
docker compose ps
如果有问题,需要单独查看报错情况,目前两次安装的不同版本都可以直接启动成功。
(5)访问系统
# 本地环境
http://localhost/install
# 本地环境
http://localhost
默认是 80 端口,如果端口冲突,需要配置端口号,在 .env 配置;
2.2 模型配置
大模型使用的是远端模型,测试的 LLM 为:
- 阿里云百炼:https://bailian.console.aliyun.com/
- DeepSeek 开放平台:https://platform.deepseek.com/
申请过程和本文主要内容关联不大,不进行展开。
2.3 MCP 配置
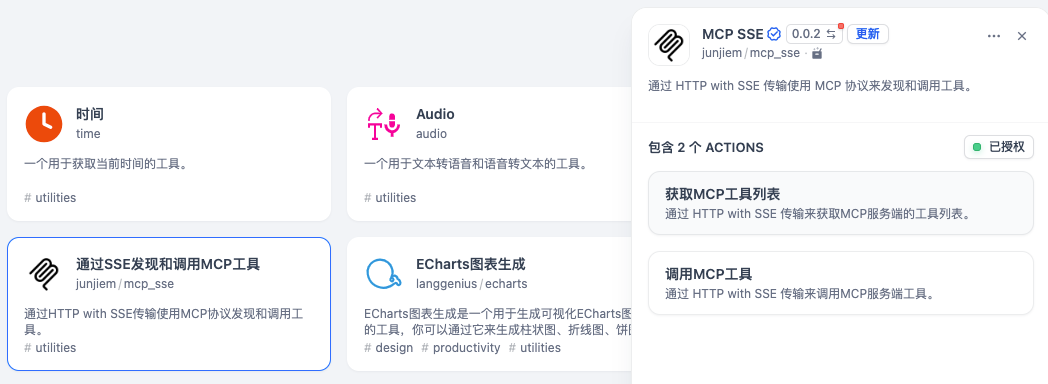
本文在 Dify 中连接 MCP Server,使用的 MCP 工具是 Dify 市场的:MCP SSE 插件。
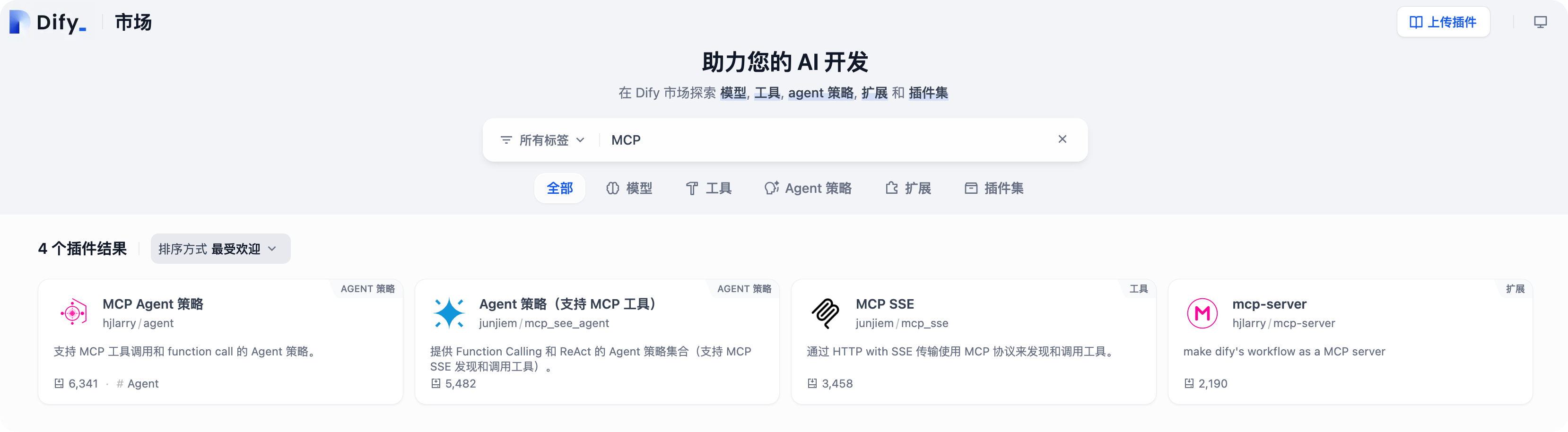
MCP SSE:通过 HTTP with SSE 传输使用 MCP 协议来发现和调用工具。
插件主页:https://marketplace.dify.ai/plugins/junjiem/mcp_sse
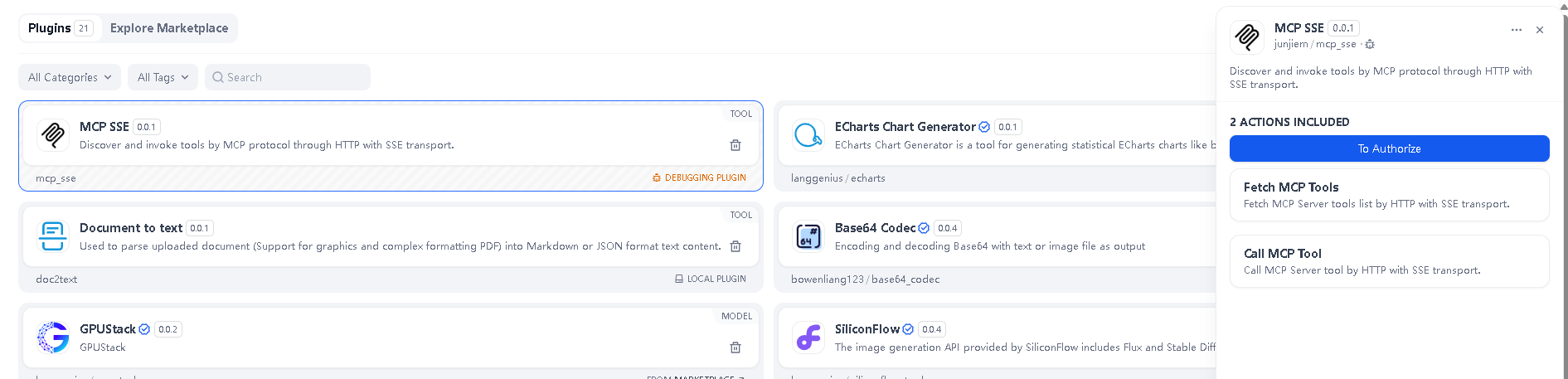
插件支持 sse 方式访问 MCP Server,不支持本地方式
http://localhost:8000/sse
MCP服务配置,支持多个MCP服务。例如:
{
"server_name1": {
"url": "http://127.0.0.1:8000/sse",
"headers": {},
"timeout": 60,
"sse_read_timeout": 300
},
"server_name2": {
"url": "http://127.0.0.1:8001/sse"
}
}
版本演进较快,如果有版本差异,可以查看新版本的使用说明
2.4 ClickHouse MCP
ClickHouse 官方 Github 提供了一个 MCP Server 版本:ClickHouse MCP Server
地址:https://github.com/ClickHouse/mcp-clickhouse
(1)工具支持
- run_select_query:在您的Clickhouse群集上执行SQL查询。使用说明:
- 输入:sql(字符串):执行的SQL查询。
- 所有ClickHouse查询均使用readonly = 1运行,以确保它们安全。
- list_databases:在您的Clickhouse群集上列出所有数据库。
- list_tables:在数据库中列出所有表。使用说明
- 输入:database(字符串):数据库的名称。
(2)配置说明
将以下变量添加到存储库根的.env文件中。
CLICKHOUSE_HOST=localhost
CLICKHOUSE_PORT=8123
CLICKHOUSE_USER=default
CLICKHOUSE_PASSWORD=clickhouse
(3)安装依赖
运行uv sync以安装依赖项(Python 相关环境),值得注意的是,Python 版本是:3.13
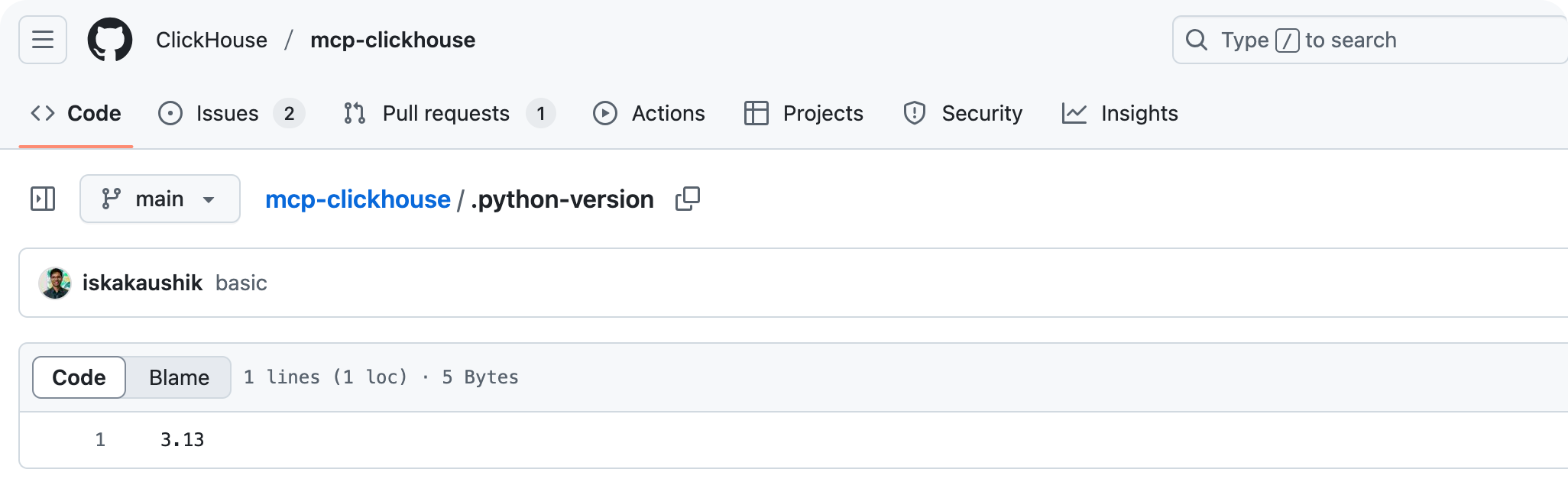
版本低的话,需要升级 Python 版本,最新版本是 3.13.2,
注意:3.13 的先行版本会报错,如果使用是 pyenv 或者 brew 安装,同样需要升级到较新版本。
(4)运行服务
项目根目录使用如下命令运行服务
mcp dev mcp_clickhouse/mcp_server.py
其中:mcp 需要 node 环境。
启动后,安装命令行中提示的地址进行连通性验证,如果 list_databases 工具可用,证明连通性已经可以。
2.5 MCP Proxy
由于 ClickHouse MCP Server 当前所用版本(20250406)无 SSE 协议支持,所以只能使用代理进行协议转换。
- 代理工具:mcp-proxy
- 项目介绍:Connect to MCP servers that run on SSE transport, or expose stdio servers as an SSE server using the MCP Proxy server.
- 项目地址:https://github.com/sparfenyuk/mcp-proxy
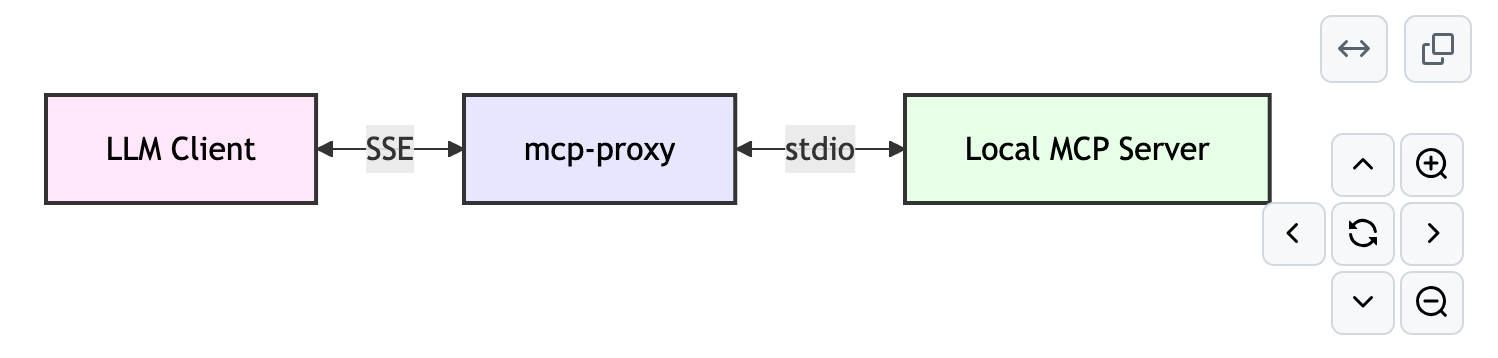
工具支持两种模式:
- stdio to SSE
- SSE to stdio
本文使用的是:SSE to stdio,原理示意图如下:
安装环境后,通过命令启动
mcp-proxy --sse-host=0.0.0.0 --sse-port=8080 --pass-environment -- mcp run mcp_clickhouse/mcp_server.py
Dify 通过 UI 进行配置
2.6 RAG 配置
为了让大模型更好的理解 SQL,可以将 ClickHouse 的建表语句导入到了知识库中
官方手册地址:https://docs.dify.ai/zh-hans/guides/knowledge-base
由于知识库支持的格式为:
- 长文本内容(TXT、Markdown、DOCX、HTML、JSON 甚至是 PDF)
- 结构化数据(CSV、Excel 等)
- 在线数据源(网页爬虫、Notion 等)
导出 ClickHouse DDL 时,可以使用 TXT 格式。
2.7 ECharts 图表插件
ECharts图表生成是一个用于生成可视化ECharts图表的工具,你可以通过它来生成柱状图、折线图、饼图等各类图表。
项目地址:https://marketplace.dify.ai/plugins/langgenius/echarts
3. 工作流配置
3.1 工作流基本配置
Dify 工作流分为两种类型:
- Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。
- Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。
本文使用的方式是 Workflow,界面截图参考官网如下
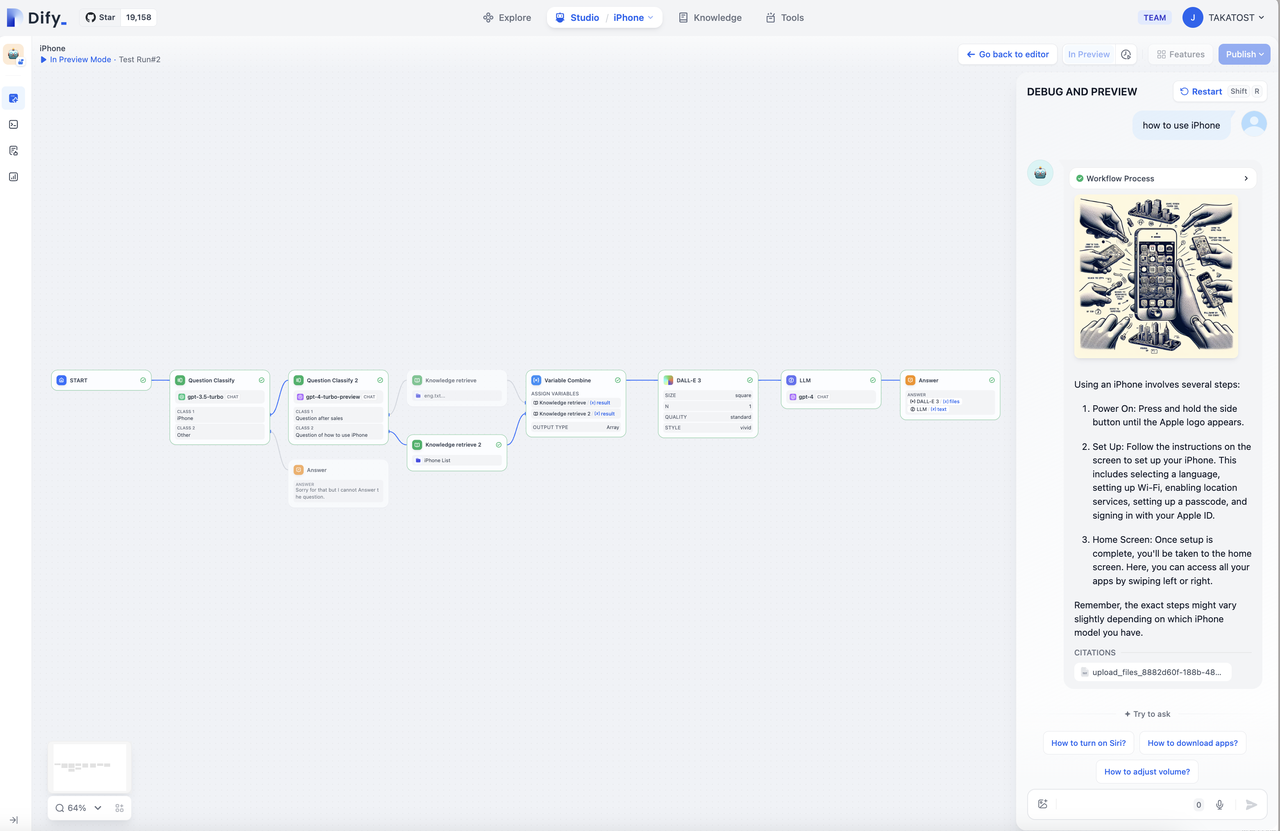
工作流配置文档较多,使用方式也较为灵活,如下是本文在配置过程中参考的一些文档,可以对工作流有大体的了解。
- DeepSeek+Dify查询数据库: https://mp.weixin.qq.com/s/7geBx9r7T5ZA_PODqiHc7A
如果需要对工作流中的每一个组件有进一步理解,可以参考官方手册
本文使用的 SQL Prompt 是
你是一名专业的数据分析师和DBA。
理解用户的原始需求,用户需求是:{{#sys.query#}}
结合知识库中提供的数据表结构信息
输出标准的查询 ClickHouse SQL 语句,供 ClickHouse 直接执行。
要求:
1. 返回内容:仅返回标准查询 SQL 语句;
2. 返回内容:不要添加其他任何内容,不要添加格式内容,如:query、SQL 等;
3. 查询语句的表名前,需要添加数据库名称。
3.2 协议兼容
在 Dify 和 ClickHouse 进行互通时,经常出现格式不兼容的情况。可以使用以下工具代码进行格式转换:
(1)工具代码:去掉 Markdown SQL 格式
去掉大模型返回的 markdown
def main(arg1: str) -> dict:
# 去掉开头的 ```sql
if arg1.startswith("```sql"):
arg1 = arg1[len("```sql"):]
# 去掉结尾的 ```
if arg1.endswith("```"):
arg1 = arg1[:-len("```")]
# 将所有的 \n 替换为空格
arg1 = arg1.replace("\n", " ")
# 去掉可能的前后空格
arg1 = arg1.strip()
return {
"result": arg1
}
(2)工具代码:JSON 转 ECharts
ClickHouse MCP 返回格式为 JSON 格式,如果想给 ECharts 插件使用,同样需要进行转换。本文试用了使用大模型进行格式转换,效果不佳,速度还慢,固定格式还是代码来的快。
import json
def main(arg1: str) -> dict:
# 结果存储
result = {
"result-1": "", # 存储 trip_mile_group 的值
"result-2": "" # 存储 vin_count 的值
}
# 解析文本内容
text_content = arg1
# 提取content部分
content_start = text_content.find("content=[") + len("content=[")
content_end = text_content.find("] isError=")
content_str = text_content[content_start:content_end]
# 分割content中的每个TextContent
text_contents = content_str.split("), ")
# 提取每个TextContent中的text字段并解析JSON
field_values = {}
field_names = []
# 处理第一个JSON对象时提取字段名称
first_json_processed = False
for tc in text_contents:
if tc.startswith("TextContent(type='text', text='"):
# 提取JSON字符串
json_str = tc[len("TextContent(type='text', text='"):]
# 如果字符串以 ')结尾,去掉这部分
if json_str.endswith("')"):
json_str = json_str[:-2]
elif not tc.endswith(")"): # 处理最后一个元素,它可能没有结尾的 )
json_str = json_str
# 处理转义字符
json_str = json_str.encode().decode('unicode_escape')
# 移除末尾的单引号(如果有)
if json_str.endswith("'"):
json_str = json_str[:-1]
try:
item = json.loads(json_str)
# 如果是第一个JSON对象,提取字段名称
if not first_json_processed:
field_names = list(item.keys())
# 初始化每个字段的值列表
for field in field_names:
field_values[field] = []
first_json_processed = True
# 将每个字段的值添加到相应的列表中
for field in field_names:
if field in item:
field_values[field].append(str(item[field]))
else:
field_values[field].append("")
except json.JSONDecodeError as e:
print(f"Error parsing JSON: {e}")
print(f"Problematic JSON string: {json_str}")
# 将提取的值用分号连接并存入result
if len(field_names) >= 2:
result["result-1"] = ";".join(field_values[field_names[0]])
result["result-2"] = ";".join(field_values[field_names[1]])
else:
print("Warning: Expected at least 2 fields in JSON objects, but found", len(field_names))
return {
"result_1": result["result-1"],
"result_2": result["result-2"]
}
其他工作流编排内容,和业务紧密关联,可以使用工作流的提供的预览与测试工具进行能力验证。
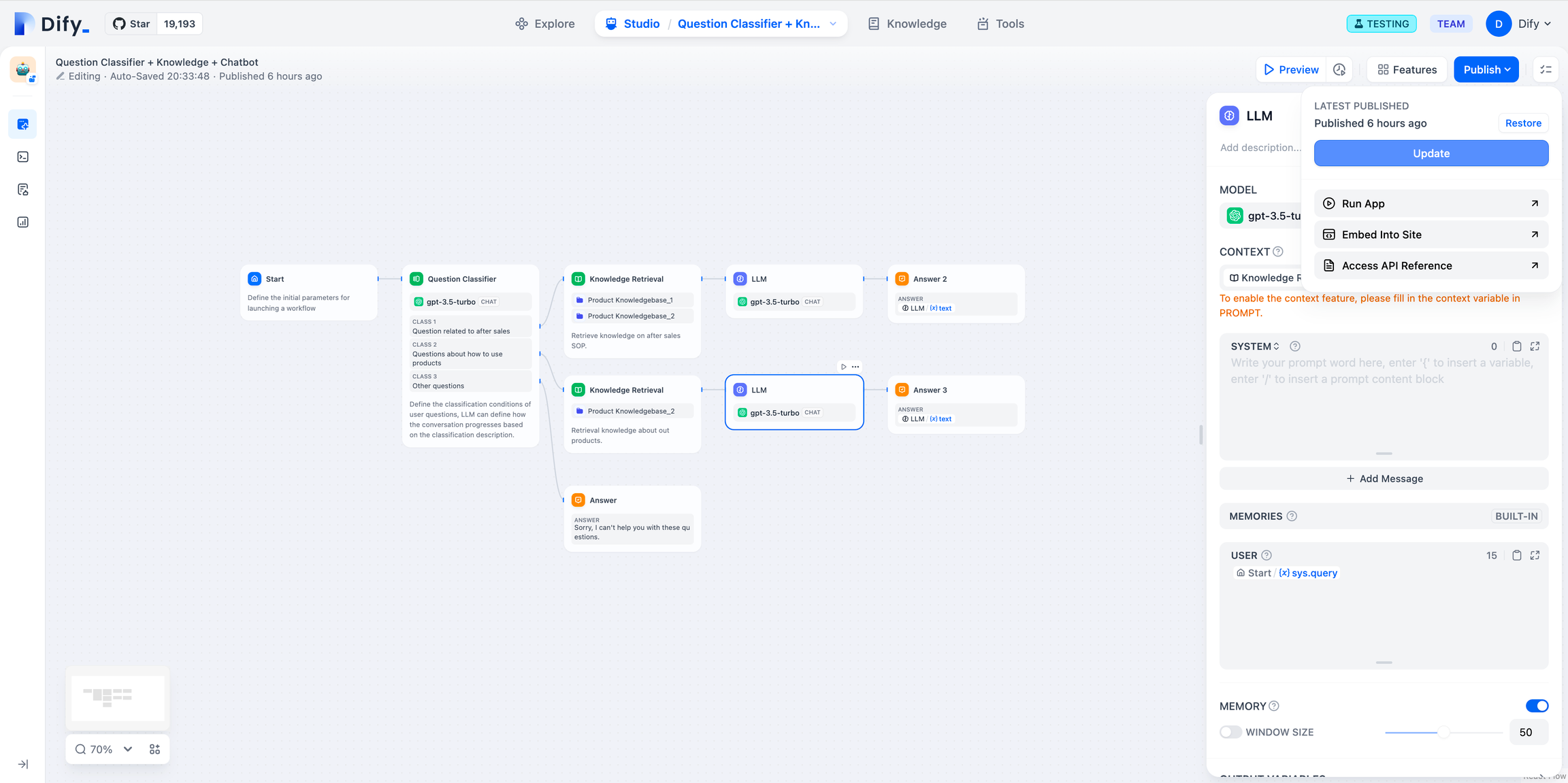
3.3 应用发布
调试完成之后点击右上角的发布,可以将该工作流保存并快速发布成为不同类型的应用。
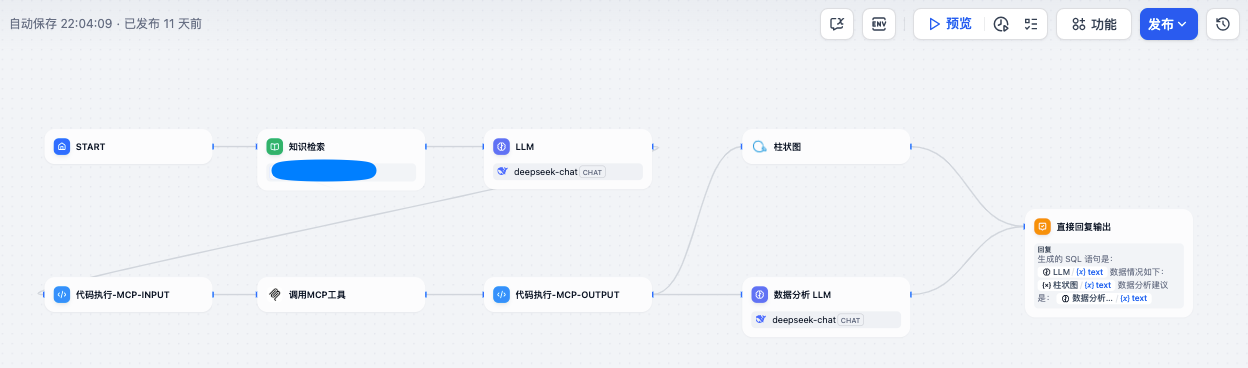
3.4 效果验证
本文使用 Dify 的对话框,通过自然语言的方式,输入用户需求,大模型理解后,输出 ClickHouse 的 SQL 语句,Dify 通过 MCP 协议访问 ClickHouse 并得到查询结果,根据结果生成图表和数据情况分析。
4. 总结与展望
在本教程中,我们详细介绍了如何在 Dify 平台中通过 MCP 协议连接 ClickHouse 数据库,实现数据分析和可视化功能。这种集成方案为开发者提供了强大的数据处理能力,使 AI 应用能够轻松访问和分析大规模数据。
主要成果
- 成功部署 Dify 平台并配置大语言模型
- 通过 MCP SSE 插件连接 ClickHouse 数据库
- 实现了数据查询、分析和可视化功能
- 构建了完整的工作流,支持交互式数据分析
未来可能的扩展
- 集成更多数据源,如 MySQL、PostgreSQL 等
- 优化查询性能,支持更复杂的数据分析场景
- 增强可视化能力,支持更多图表类型
- 结合 RAG 技术,实现更智能的数据分析和问答功能
如果您对 AI 应用开发感兴趣,可以参考我的其他文章:
希望本教程对您有所帮助,如有问题或建议,欢迎在评论区留言讨论!
预祝配置过程中顺利

Good Job(Photo by Luke Thornton on Unsplash )