- Published on
18种RAG技术实战对比:从简单RAG到自适应RAG全面解析
- Authors

- Name
- Shoukai Huang
18种RAG技术实战对比与实现
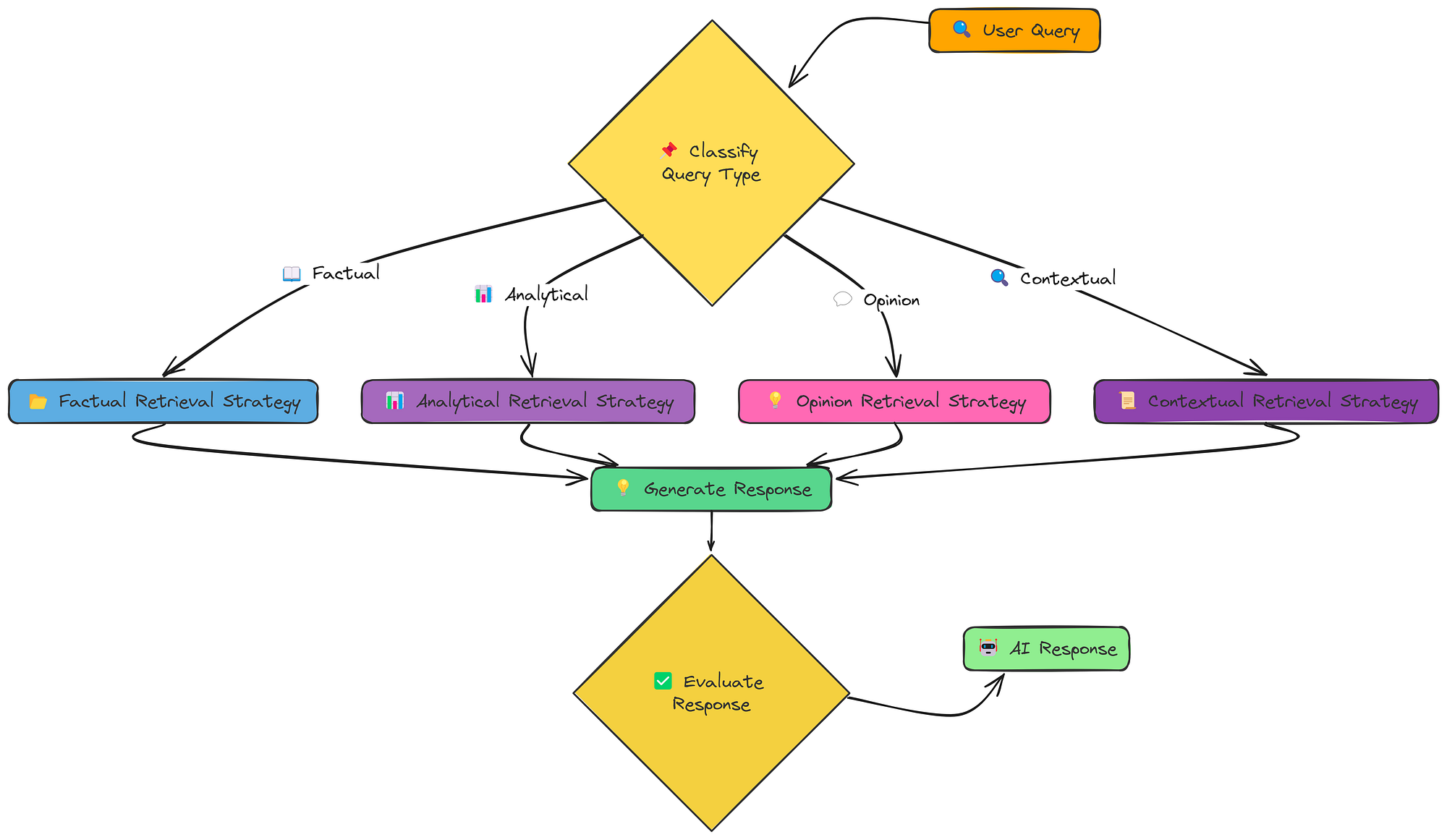
自适应 Rag 工作流程(由Fareed Khan创建)
本文是对一篇测试18种RAG技术的英文文章的翻译整理,文章从不同维度展示了RAG实现思路,全部使用基础库而非框架构建,非常适合作为理解RAG技术的入门教程。
目录
- 原文信息
- GitHub仓库
- 测试查询和LLMs
- 结论:最有效的技术
- 开始导入库
- 01-简单的RAG
- 02-语义分块
- 03-分层索引
- 04-融合RAG
- 05-CRAG
- 06-反馈循环RAG
- 07-自适应RAG
- 08-重排序器
- 09-图RAG
- 10-层次RAG
- 11-HyDE RAG
- 12-CRAG
- 13-反馈循环RAG
- 14-自适应RAG
- 15-重排序器
- 16-图RAG
- 17-层次RAG
- 18-HyDE RAG
- 结论
原文信息
翻译自:Testing 18 RAG Techniques to Find the Best
从都知道的简单 RAG 方法开始,然后测试更先进的技术,如 CRAG、Fusion、HyDE 等!
为了让一切变得简单……
没有使用 LangChain 或 FAISS
但是只使用基本库来以Jupyter 笔记本风格编写所有技术,以保持简单和易于学习。
GitHub 仓库
所有分步笔记本均可在此处找到:
https://github.com/FareedKhan-dev/all-rag-techniques
代码库组织如下:
│ │ 1_simple_rag.ipynb
│ ── 2_semantic_chunking.ipynb
│
── 9_rse.ipynb
│ ── 10_contextual_compression.ipynb
│ ── 11_feedback_loop_rag.ipynb
│ ── 12_adaptive_rag.ipynb │
──
17_graph_rag.ipynb
│ ── 18_hierarchy_rag.ipynb
│ ── 19_HyDE_rag.ipynb
│ ── 20_crag.ipynb
└── data/
└── val.json
└── AI_information.pdf
└──tention_is_all_you_need.pdf
测试查询和 LLMs
为了全面评估各种RAG技术的效果,作者设计了一套完整的测试环境:
为了测试每种技术,我们需要四样东西:
- 测试查询及其真实答案。
- 将应用 RAG 的 PDF 文档。
- 嵌入生成模型。
- 响应和验证 LLM。
使用Claude 3.5 思维模型,我创建了一份长达 16 页的AI 主题文档作为 RAG 的参考文档,而Attention 就是您评估多模型 RAG 所需的全部 文件。它位于我的验证数据文件夹中,并且经过智能策划以测试我们将要使用的所有技术。
对于响应生成和验证,我们将使用 LLaMA-3.2–3B Instruct 来测试小型 LLM 在 RAG 任务中的表现如何。
对于嵌入,我们将使用 TaylorAI/gte-tiny 模型。
我们的测试查询很复杂,我们将在整个文档中使用它,它的真实答案是:
test query:
How does AI’s reliance on massive data sets act as a double-edged sword?
True Answer:
It drives rapid learning and innovation while also
risking the amplification of inherent biases,
making it crucial to balance data volume with fairness and quality.
结论:最有效的技术!
💡 经过18种RAG技术的对比测试,自适应RAG(Adaptive RAG)以0.86的最高分明显胜出
在我们的测试查询中测试了 18 种不同的 RAG 技术之后,最好将它写在顶部,而不是在最后提供它。
通过智能地对查询进行分类,并为每种问题类型选择最合适的检索策略,Adaptive RAG 比其他方法表现出更好的性能。它能够在事实、分析、观点和上下文策略之间动态切换,从而能够以惊人的准确性处理各种信息需求。
虽然分层索引(0.84)、融合(0.83)和 CRAG(0.824)等技术的表现也很出色,但自适应 RAG 的灵活性使其在实际应用中占据优势。
开始导入库
首先需要克隆代码仓库并安装必要的依赖项:
让我们首先克隆我的 repo 以便安装所需的依赖项并开始工作。
# Cloning the repo
git clone https://github.com/FareedKhan-dev/all-rag-techniques.git
cd all-rag-techniques
安装所需的依赖项。
# Installing the required libraries
pip install -r requirements.txt
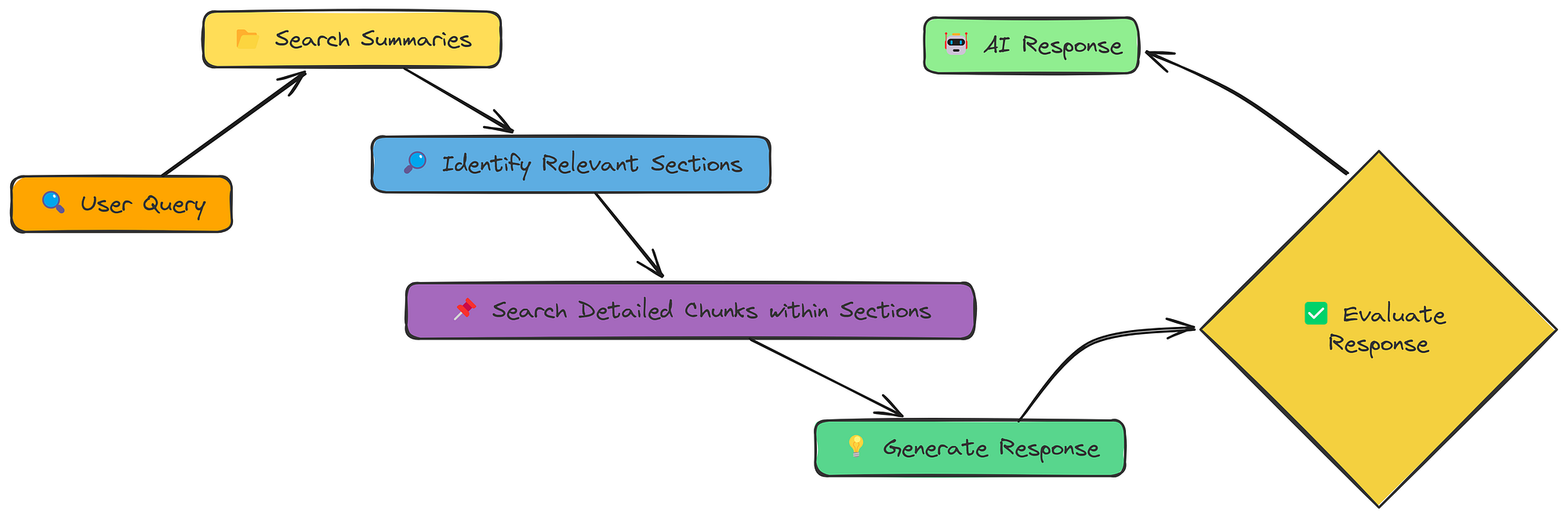
01-简单的 RAG
让我们从最基础的RAG实现开始,理解其工作原理并评估其效果:
让我们从最简单的 RAG 开始。首先,我们将直观地了解它的工作原理,然后对其进行测试和评估。
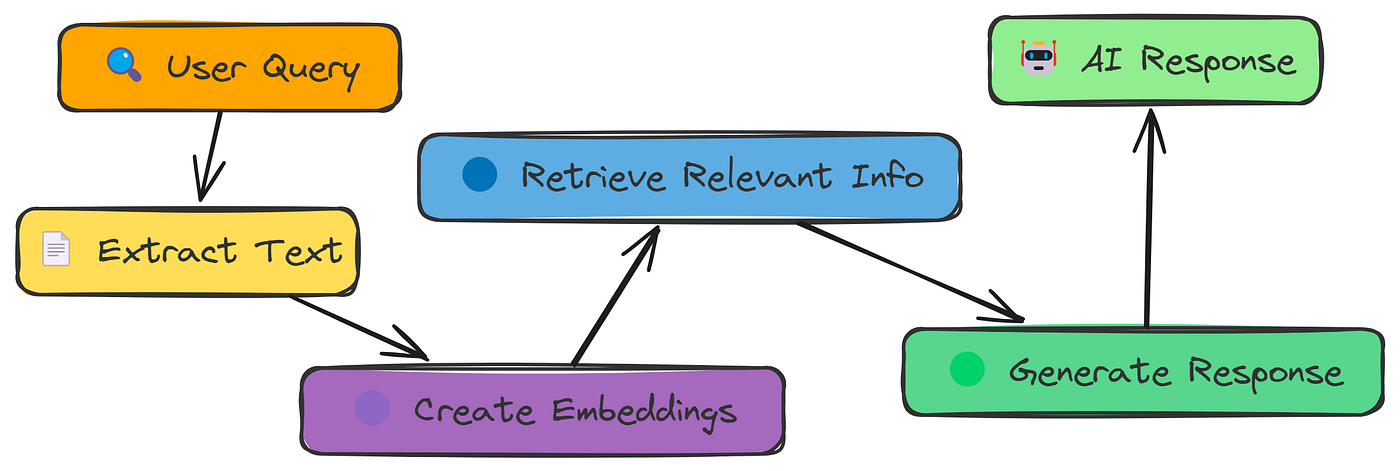
Simple RAG workflow (Created by Fareed Khan)
如图所示,简单 RAG 管道的工作原理如下:
- 从 PDF 中提取文本。
- 将文本分成更小的块。
- 将块转换为数字嵌入。
- 根据查询搜索最相关的块。
- 使用检索到的块生成响应。
- 将答案与正确答案进行比较以评估准确性。
首先,让我们加载文档,获取文本,并将其分成可管理的块:
# 定义 PDF 文件的路径
pdf_path = "data/AI_information.pdf"
# 从 PDF 文件中提取文本,并创建更小、重叠的块。extracted_text
extracted_text = extract_text_from_pdf(pdf_path)
text_chunks = chunk_text(extracted_text, 1000, 200)
print("Number of text chunks:", len(text_chunks))
### OUTPUT ###
Number of text chunks: 42
此代码用于extract_text_from_pdf从中提取所有文本PDF file。然后,chunk_text将大文本块分解为较小的、重叠的部分,每个部分约为1000 characters long。
接下来,我们需要将它们text chunks变成numerical representations (embeddings):
# 为文本块创建嵌入
response = create_embeddings(text_chunks)
这里,create_embeddings获取我们的列表text chunks并使用我们的嵌入模型为每个列表生成一个numerical embedding。这些嵌入捕获了meaning of the text。
现在我们可以执行semantic search,找到chunks most relevant我们的测试查询:
# 我们的测试查询,并执行语义搜索。query
query = '''How does AI's reliance on massive data sets act
as a double-edged sword?'''
top_chunks = semantic_search(query, text_chunks, embeddings, k=2)
然后,semantic_search将查询嵌入与进行比较chunk embeddings,返回most similar chunks。
利用我们relevant chunks现有的,让我们生成一个response:
# 定义 AI 助手的系统提示
system_prompt = "You are an AI assistant that strictly answers based on the given context. If the answer cannot be derived directly from the provided context, respond with: 'I do not have enough information to answer that.'"
# 根据顶部块创建用户提示,并生成 AI 响应。
user_prompt = "\n".join([f"Context {i + 1}:\n{chunk}\n========\n" for i, chunk in enumerate(top_chunks)])
user_prompt = f"{user_prompt}\nQuestion: {query}"
ai_response = generate_response(system_prompt, user_prompt)
print(ai_response.choices[0].message.content)
此代码将 格式化retrieved chunks为prompt。large language model (LLM)该generate_response函数将此提示发送给,后者仅根据提供的LLM制作。answercontext
simple RAG最后,让我们看看我们的表现如何:
# 定义评估系统的系统提示
evaluate_system_prompt = "You are an intelligent evaluation system tasked with assessing the AI assistant's responses. If the AI assistant's response is very close to the true response, assign a score of 1. If the response is incorrect or unsatisfactory in relation to the true response, assign a score of 0. If the response is partially aligned with the true response, assign a score of 0.5."
# 创建评估提示并生成评估响应
evaluation_prompt = f"User Query: {query}\nAI Response:\n{ai_response.choices[0].message.content}\nTrue Response: {data[0]['ideal_answer']}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTPUT ###
... Therefore, the score of 0.3 being not very close to the
true response, and not perfectly aligned.
嗯… simple rag 的响应低于平均水平
让我们继续讨论下一个方法。
02-语义分块
🔍 语义分块通过理解内容含义来智能划分文本,而不是简单地按固定大小切分
在我们的简单 RAG 方法中,我们只是将文本切成固定大小的块。这很粗糙!它可能会将一个句子分成两半,或者将不相关的句子组合在一起。
语义分块旨在变得更加智能。它不采用固定大小,而是尝试根据含义来拆分文本,将语义相关的句子分组在一起。
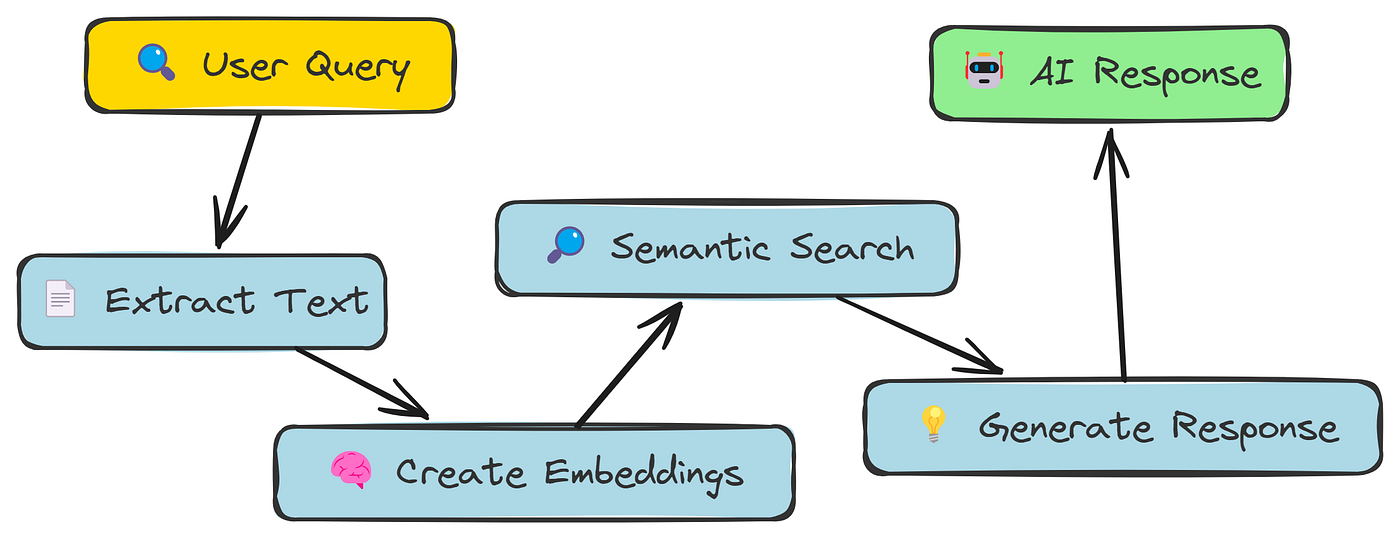
语义分块工作流程(由Fareed Khan创建)
这个想法是,如果句子谈论的是类似的事情,那么它们应该在同一个块中。我们将使用相同的嵌入模型来判断句子的相似程度。
# 将文本拆分成句子(基本拆分)
sentences = extracted_text.split(". ")
# 为每个句子生成
embeddings = [get_embedding(sentence) for sentence in sentences]
print(f"Generated {len(embeddings)} sentence embeddings.")
### OUTPUT ###
233
此代码将我们的提取文本拆分成单独的句子。然后为每个单独的句子创建嵌入。
现在,我们来计算连续句子之间的相似度:
# 计算连续句子之间的相似度
similarities = [cosine_similarity(embeddings[i], embeddings[i + 1]) for i in range(len(embeddings) - 1)]
此cosine_similarity函数(我们之前定义过)告诉我们两个embeddings的相似程度。得分为1表示它们相似very similar,得分0为 表示它们相似completely different。我们为每一对 计算此得分adjacent sentences。
Semantic chunking决定在哪里split the text into chunks。我们将使用一种"breakpoint"方法。我们percentile method在这里使用,寻找big drops in similarity:
# 使用百分位数法计算断点,阈值为 90
breakpoints = compute_breakpoints(similarities, method="percentile", threshold=90)
该compute_breakpoints函数使用"percentile"方法识别similarity句子之间的点drops significantly。这些就是我们的chunk boundaries。
现在我们可以创建我们的semantic chunks:
# 使用 split_into_chunks 函数创建块
text_chunks = split_into_chunks(sentences, breakpoints)
print(f"Number of semantic chunks: {len(text_chunks)}")
### OUTPUT ###
Number of semantic chunks: 145
split_into_chunks获取我们发现的列表sentences和breakpoints并将句子分组到chunks。
接下来,我们需要创建embeddings这些chunks:
# 使用 create_embeddings 函数创建块嵌入
chunk_embeddings = create_embeddings(text_chunks)
生成响应的时间:
# Create the user prompt based on the top chunks
user_prompt = "\n".join([f"Context {i + 1}:\n{chunk}\n=====================================\n" for i, chunk in enumerate(top_chunks)])
user_prompt = f"{user_prompt}\nQuestion: {query}"
# Generate AI response
ai_response = generate_response(system_prompt, user_prompt)
print(ai_response.choices[0].message.content)
最后,评价:
# 结合用户查询、AI 响应、真实响应和评估系统提示创建评估提示
evaluation_prompt = f"User Query: {query}\nAI Response:\n{ai_response.choices[0].message.content}\nTrue Response: {data[0]['ideal_answer']}\n{evaluate_system_prompt}"
# 使用评估系统提示和评估提示生成评估响应
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
# 打印评估响应
print(evaluation_response.choices[0].message.content)
### OUTPUT
Based on the evaluation criteria,
I would assign a score of 0.2 to the AI assistant response.
评估者只给出了 0.2 分
虽然语义分块在理论上听起来不错,但它并没有帮助我们。事实上,与简单的固定大小分块相比,我们的分数下降了!
这表明,仅仅改变分块策略并不能保证胜利。我们需要采取更复杂的方法。让我们在下一节中尝试其他方法。
03-上下文丰富检索
我们发现,语义分块虽然在原则上是一个好主意,但实际上并没有改善我们的结果。
一个问题是,即使是语义定义的块也可能过于集中。它们可能会缺少周围文本中的关键背景。
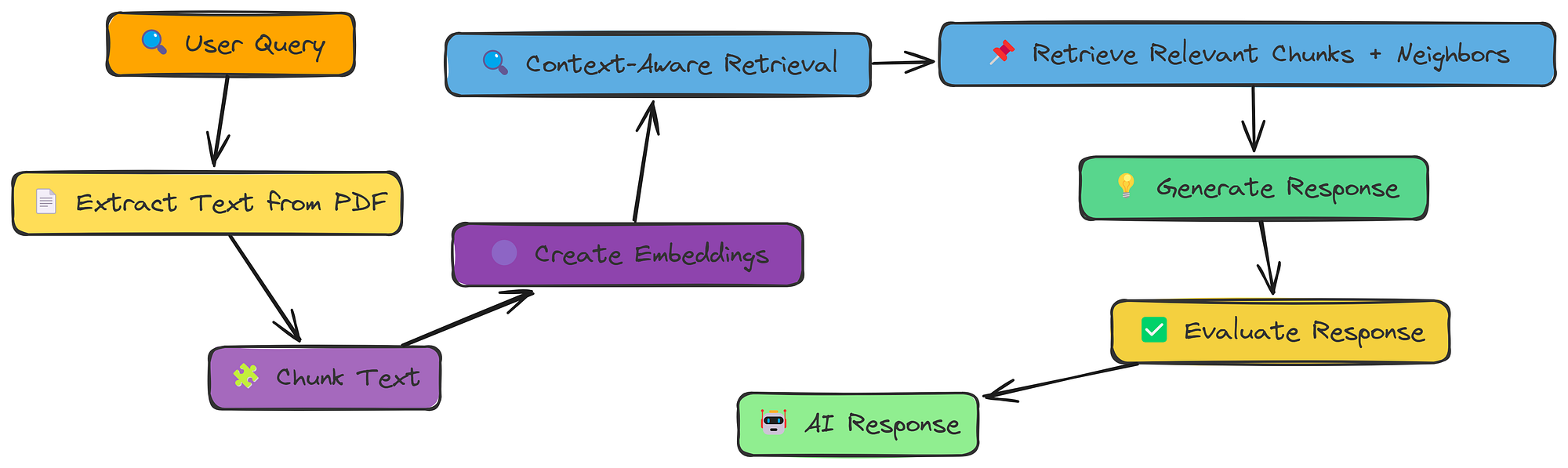
上下文丰富的工作流程(由Fareed Khan创建)
上下文丰富的检索通过抓取最匹配的块以及其邻居来解决这个问题。
让我们看看它在代码中是如何工作的。我们需要一个新函数context_enriched_search来处理retrieval:
def context_enriched_search ( query, text_chunks, embeddings, k= 1 , context_size= 1 ):
"""
检索最相关的块及其相邻块。
"""
# 将查询转换为嵌入向量
query_embedding = create_embeddings(query).data[ 0 ].embedding
similarity_scores = []
# 计算查询与每个文本块嵌入之间的相似度分数
for i, chunk_embedding in enumerate (embeddings):
# 计算查询嵌入与当前块嵌入之间的余弦相似度
similarity_score = cosine_similarity(np.array(query_embedding), np.array(chunk_embedding.embedding))
# 将索引和相似度分数存储为元组
similarity_scores.append((i, similarity_score))
# 按降序对相似度分数进行排序(相似度最高者优先)
similarity_scores.sort(key= lambda x: x[ 1 ], reverse= True )
# 获取最相关块的索引
top_index = similarity_scores[ 0 ][ 0 ]
# 定义上下文包含的范围
# 确保不低于 0 或超出 text_chunks 的长度
start = max ( 0 , top_index - context_size)
end = min ( len (text_chunks), top_index + context_size + 1 )
# 返回相关块及其相邻的上下文块
return [text_chunks[i] for i in range (start, end)]
核心逻辑与我们之前的类似search,但不是仅仅返回单个最好的chunk,而是抓取它周围的一个"window"。chunks控制我们在两边包含context_size多少个。chunks
让我们在 RAG 管道中使用它。我们将跳过文本提取和分块步骤,因为它们与 Simple RAG 中的相同。
我们将使用固定大小的块,就像我们在简单 RAG 部分中所做的那样,并且我们保持 chunk_size = 1000 和 override = 200。
现在生成一个响应,与以前相同:
# Create the user prompt based on the top chunks
user_prompt = "\n".join([f"Context {i + 1}:\n{chunk}\n=====================================\n" for i, chunk in enumerate(top_chunks)])
user_prompt = f"{user_prompt}\nQuestion: {query}"
# Generate AI response
ai_response = generate_response(system_prompt, user_prompt)
print(ai_response.choices[0].message.content)
最后,评估:
# Create the evaluation prompt and generate the evaluation response
evaluation_prompt = f"User Query: {query}\nAI Response:\n{ai_response.choices[0].message.content}\nTrue Response: {data[0]['ideal_answer']}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTUT ###
Based on the evaluation criteria,
I would assign a score of 0.6 to the AI assistant response.
这次,我们得到的评价分数是0.6!
这比简单 RAG(0.5)和语义分块(0.1)有了显著的改进。
通过包含相邻的块,我们为 LLM 提供了更多的工作背景,并且它产生了更好的答案。
我们仍不完美,但我们肯定在朝着正确的方向前进。这表明上下文对于检索有多么重要。
04-上下文块头
我们已经看到,通过包含相邻块来添加上下文很有帮助。但如果块本身的内容缺少重要信息怎么办?
通常,文档具有清晰的结构标题、标题、副标题,可提供关键背景。上下文块标头 (CCH) 利用了此结构。
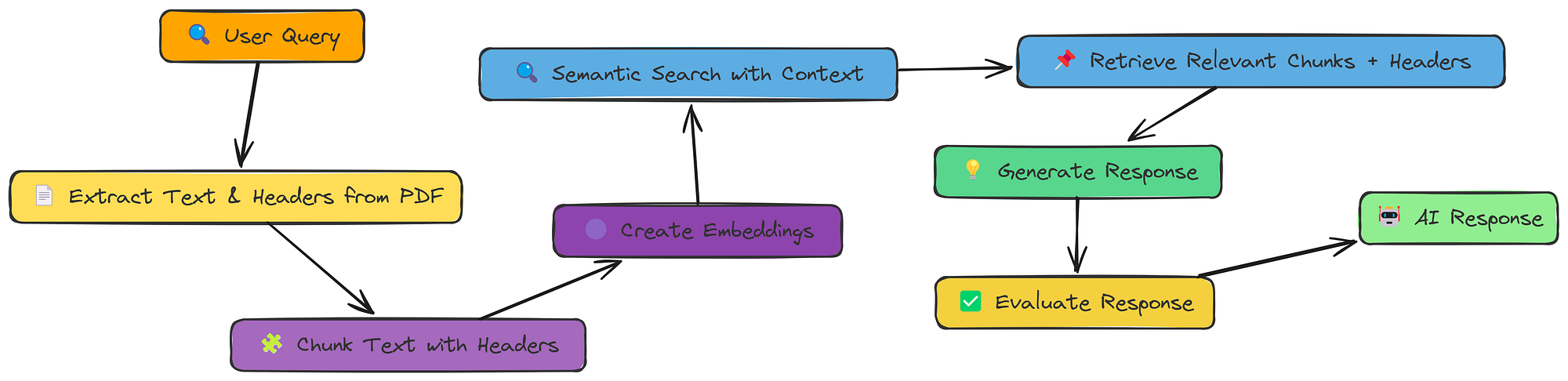
上下文块头(由Fareed Khan创建)
这个想法很简单:在创建嵌入之前,我们先在每个块前面添加一个描述性标题。这个标题就像一个迷你摘要,为检索系统(和 LLM)提供了更多可用的功能。
该generate_chunk_header函数将分析每一段文本并生成一个简洁、有意义的标题来总结其内容。这有助于有效地组织和检索相关信息。
# 将提取的文本分块,这次生成标题
text_chunks_with_headers = chunk_text_with_headers(extracted_text, 1000, 200)
# 打印一个样本以查看它是什么样子
print("Sample Chunk with Header:")
print("Header:", text_chunks_with_headers[0]['header'])
print("Content:", text_chunks_with_headers[0]['text'])
### OUTPUT ###
Sample Chunk with Header:
Header: A Description about AI Impact
Content: AI has been an important part of society since ...
看到每个块现在都有一个标题和原始文本了吗?这就是我们将要使用的增强数据。
现在来看看嵌入。我们将为标题和文本创建嵌入:
# 为每个块生成嵌入(标题和文本)
embeddings = []
for chunk in tqdm(text_chunks_with_headers, desc="Generating embeddings"):
text_embedding = create_embeddings(chunk["text"])
header_embedding = create_embeddings(chunk["header"])
embeddings.append({"header": chunk["header"], "text": chunk["text"], "embedding": text_embedding, "header_embedding": header_embedding})
我们循环遍历块,获取标题和文本的嵌入,并将所有内容存储在一起。这为检索系统提供了两种将块与查询匹配的方法。
由于semantic_search已经可以使用嵌入,我们只需确保标题和文本块都正确嵌入即可。这样,当我们执行搜索时,模型可以同时考虑高级摘要(标题)和详细内容(块文本)以找到最相关的信息。
现在,让我们修改检索步骤,不仅返回匹配的块,还返回它们的标题,以获得更好的上下文并生成响应。
# 使用查询和新的嵌入执行语义搜索
top_chunks = semantic_search(query, embeddings, k=2)
# 根据顶部块创建用户提示。注意:无需添加标题
# 因为上下文已经使用标题和块创建
user_prompt = "\n".join([f"Context {i + 1}:\n{chunk['text']}\n=====================================\n" for i, chunk in enumerate(top_chunks)])
user_prompt = f"{user_prompt}\nQuestion: {query}"
# Generate AI response
ai_response = generate_response(system_prompt, user_prompt)
print(ai_response.choices[0].message.content)
### OUTPUT ###
Evaluation Score: 0.5
这次我们的评价分数是0.5!
通过添加这些上下文标题,我们让系统有更好的机会找到正确的信息,也让 LLM 有更好的机会生成完整而准确的答案。
这显示了在数据进入检索系统之前增强数据的强大功能。我们没有改变核心 RAG 管道,但我们让数据本身更具信息量。
05-文档增强
我们已经了解了在块周围添加上下文(使用邻居或标题)可以带来哪些帮助。现在,让我们尝试一种不同的增强方法:从文本块中生成问题。
这个想法是,这些问题可以作为替代“查询”,可能比原始文本块本身更符合用户的意图。
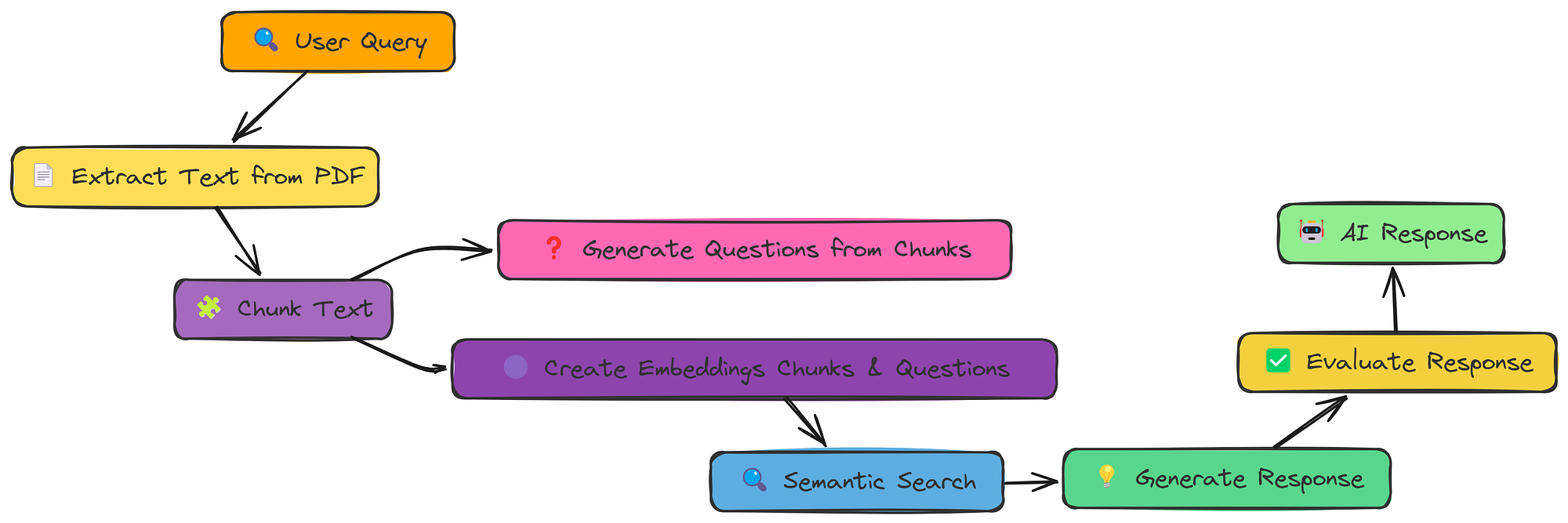
文档增强工作流程(由Fareed Khan创建)
chunking我们在和之间添加这个步骤embedding creation。我们可以简单地使用generate_questions函数来实现这一点。它接受一个text_chunk并返回可以使用它生成的一些问题。
让我们首先看看如何通过问题生成实现文档增强:
# 处理文档(提取文本、创建块、生成问题、构建向量存储)
text_chunks, vector_store = process_document(
pdf_path,
chunk_size=1000,
chunk_overlap=200,
questions_per_chunk=3
)
print(f"Vector store contains {len(vector_store.texts)} items")
### OUTPUT ###
Vector store contains 214 items
在这里,process_document函数可以完成所有工作。它接受pdf_path、chunk_size、overlap和questions_per_chunk并返回vector_store。
现在,vector_store不仅包括文档的嵌入,还包括生成的问题的嵌入。
现在,我们可以像以前一样使用这个进行语义搜索vector_store。我们在这里使用一个简单的函数来查找相似的向量。
# 执行语义搜索,找到相关内容
search_results = semantic_search(query, vector_store, k=5)
print("Query:", query)
print("\nSearch Results:")
# 按类型组织结果
chunk_results = []
question_results = []
for result in search_results:
if result["metadata"]["type"] == "chunk":
chunk_results.append(result)
else:
question_results.append(result
这里最重要的变化是我们如何处理搜索结果。现在我们的向量存储中有两种类型的项目:原始文本块和生成的问题。此代码将它们分开,因此我们可以看到哪种类型的内容与查询最匹配。
最后的步骤,生成上下文然后进行评估:
# 从搜索结果准备上下文
context = prepare_context(search_results)
# 生成响应
response_text = generate_response(query, context)
# 从验证数据中获取参考答案
reference_answer = data[ 0 ][ 'ideal_answer' ]
# 评估响应
evaluation = evaluate_response(query, response_text, reference_answer)
print("\nEvaluation:")
print(evaluation)
### OUTPUT ###
Based on the evaluation criteria, I would assign a
score of 0.8 to the AI assistants response.
我们的评估显示分数在0.8左右!
生成问题并将其添加到我们的可搜索索引中使我们的性能再次得到提升。
有时候,问题似乎比原始文本块更能表达信息需求。
06-查询转换
到目前为止,我们一直专注于改进 RAG 系统使用的数据。但是查询本身呢?
通常,用户提出问题的方式并不是搜索知识库的最佳方式。查询转换旨在解决此问题。我们将探索三种不同的方法:
- **查询重写:**使查询更加具体和详细。
- **后退提示:**创建更广泛、更通用的查询来检索背景内容。
- **子查询分解:**将复杂的查询分解为多个更简单的子查询。
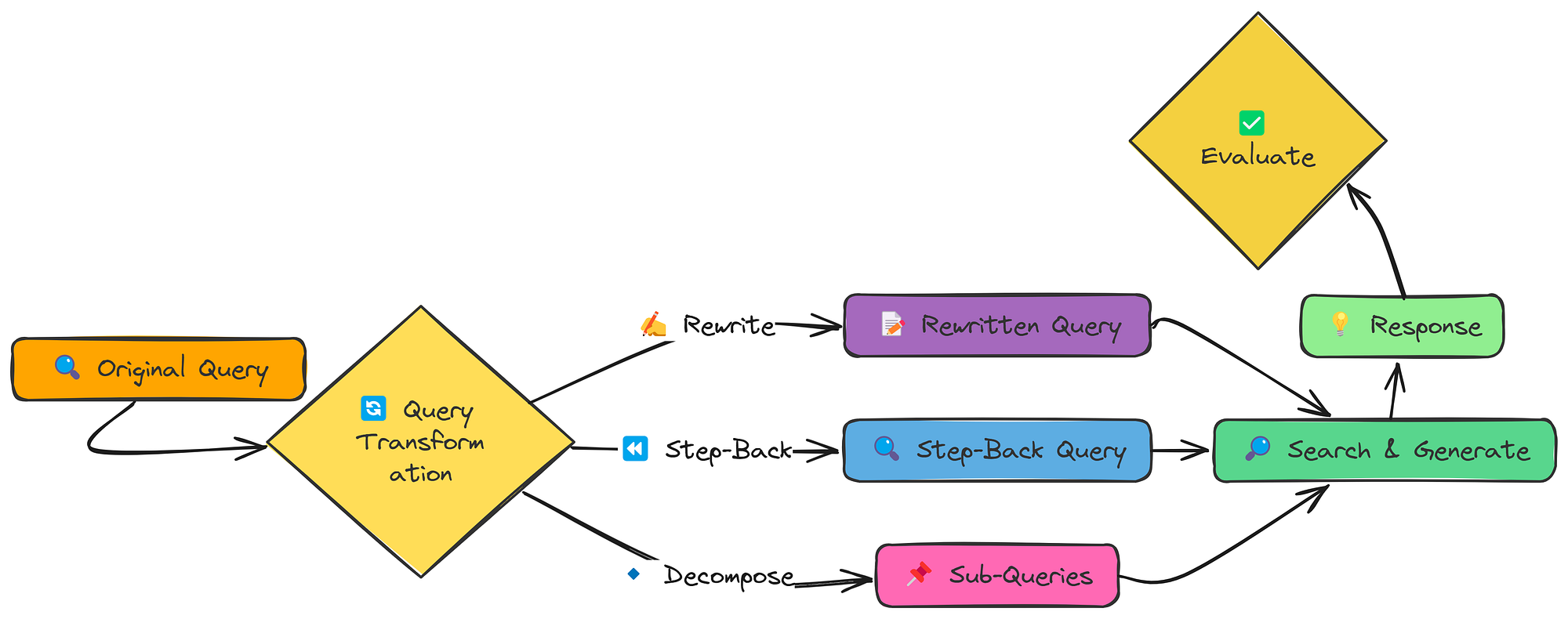
查询转换工作流(由Fareed Khan创建)
让我们看看这些转换的实际效果。我们将使用标准测试查询:
# 查询重写
rewritten_query = rewrite_query(query)
# 后退提示
step_back_query = generate_step_back_query(query)
generate_step_back_query与重写相反:它创建一个更广泛的查询,可能会检索有用的背景信息。
最后,子查询分解:
# 子查询分解
sub_queries = decompose_query(query, num_subqueries=4)
decompose_query将原始查询分解为几个更小、更集中的问题。其理念是,这些子查询结合起来,可能比任何单个查询更好地涵盖原始查询的意图。
现在,为了了解这些转换如何影响我们的 RAG 系统,让我们使用一个结合了所有以前方法的函数:
def rag_with_query_transformation(pdf_path, query, transformation_type=None):
"""
使用可选的查询转换运行完整的 RAG 管道。Args
:
pdf_path(str):PDF 文档的路径
query(str):用户查询
transformation_type(str):转换类型(无、'rewrite'、'step_back' 或 'decompose')
返回:
Dict:包括查询、转换后的查询、上下文和响应的结果
"""
# 处理文档以创建向量存储
vector_store = process_document(pdf_path)
# 应用查询转换和搜索
if transformation_type:
# 使用转换后的查询执行搜索
results = formed_embeddings(query, vector_store, transformation_type)
else:
# 执行不进行转换的常规搜索
query_embeddings = create_embeddings(query)
results = vector_store.similarity_search(query_embedding, k= 3 )
# 从搜索结果中合并上下文
context = "\n\n" .join([ f"PASSAGE {i+ 1 } :\n {result[ 'text' ]} " for i, result in enumerate (results)])
# 根据查询和组合上下文生成响应
response = generate_response(query, context)
# 返回包括原始查询、转换类型、上下文和响应的结果
return {
"original_query": query,
"transformation_type": transformation_type,
"context": context,
"response": response
}
evaluate_transformations函数通过不同的查询转换技术(重写、后退和分解)运行原始查询,然后比较它们的输出。
这有助于我们了解哪种方法可以检索最相关的信息以获得更好的响应。
# Run evaluation
evaluation_results = evaluate_transformations(pdf_path, query, reference_answer)
print(evaluation_results)
### OUTPUT ###
Evaluation Score: 0.5
评估分数为0.5。
这表明我们的查询转换技术并不总是优于简单的方法。
虽然查询转换功能非常强大,但它们并不是灵丹妙药。有时,原始查询已经是格式正确的,试图“改进”它实际上可能会让事情变得更糟。
07-重排器(reranker)
我们尝试改进数据(使用分块策略)和查询(使用转换)。现在,让我们关注检索过程本身。简单的相似性搜索通常会返回相关和不相关的结果。
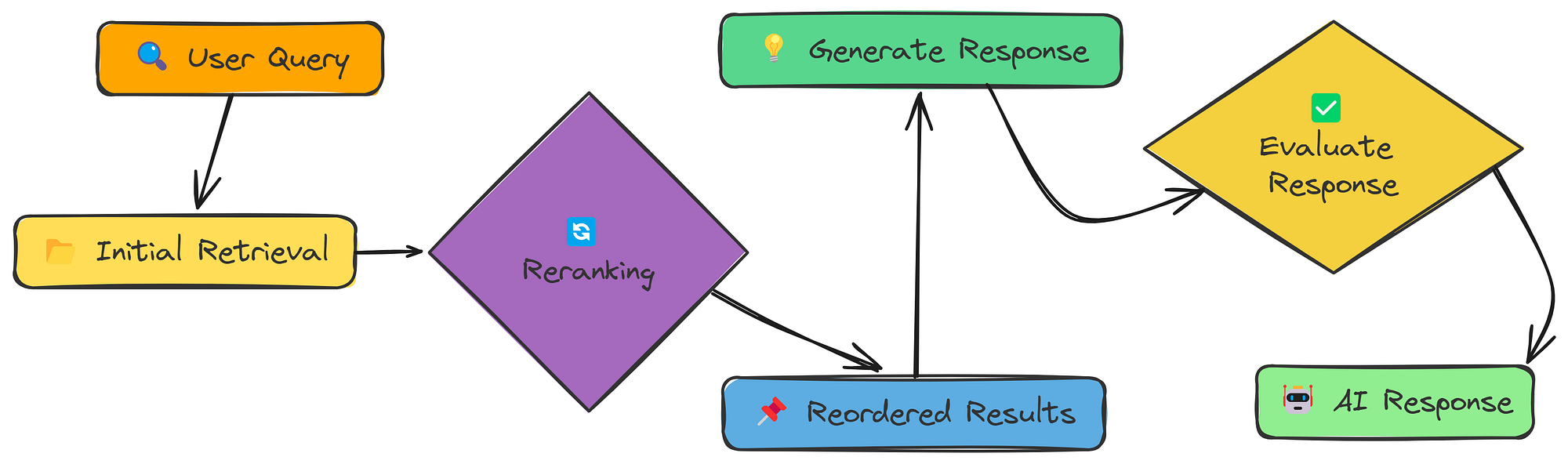
Reranker(由Fareed Khan创建)
重新排序是第二遍,对最初检索到的结果进行重新排序,将最佳结果放在最上面。
该rerank_with_llm函数获取初始检索到的块并使用 LLM 根据相关性对其进行重新排序。这有助于确保最有用的信息首先出现。
重新排序后,我们称之为的最终函数将generate_final_response获取重新排序的块,将其格式化为提示,然后将其发送到 LLM 以生成最终响应。
def rag_with_reranking ( query, vector_store, reranking_method= "llm" , top_n= 3 , model= "meta-llama/Llama-3.2-3B-Instruct" ):
"""
完成包含重新排名的 RAG 管道。
"""
# 创建查询嵌入
query_embedding = create_embeddings(query)
# 初始检索(获取比重新排名所需更多的数据)
initial_results = vector_store.similarity_search(query_embedding, k= 10 )
# 应用重新排名
if reranking_method == "llm" :
reranked_results = rerank_with_llm(query, initial_results, top_n=top_n)
elif reranking_method == "keywords" :
reranked_results = rerank_with_keywords(query, initial_results, top_n=top_n) # 我们不使用它。
else :
# 不重新排名,只使用初始检索中的顶级结果
reranked_results = initial_results[:top_n]
# 结合重新排名结果中的上下文
context = "\n\n===\n\n" .join([result[ "text" ] for result in reranked_results])
# 根据上下文生成响应
response = generate_response(query, context, model)
return {
"query" : query,
"reranking_method" : reranking_method,
"initial_results" : initial_results[:top_n],
"reranked_results" : reranked_results,
"context" : context,
"response" : response
}
它需要一个query、一个vector_store(我们已经创建了)和一个reranking_method。我们使用“llm”进行基于 LLM 的重新排序。该函数执行初始检索,调用rerank_with_llm以重新排序结果,然后生成响应。
在笔记本中定义了rerank_with_keywords但我在这里没有使用它。
让我们运行它并看看它是否能改善我们的结果:
# 使用基于 LLM 的重新排名运行 RAG
llm_reranked_result = rag_with_reranking(query, vector_store, reranking_method="llm")
# Evaluate.
evaluation_prompt = f"User Query: {query}\nAI Response:\n{llm_reranked_result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTPUT ###
Evaluation score is 0.7
我们的评估分数现在约为0.7!
重新排序为我们带来了显著的改进。通过使用 LLM 直接对每个检索到的文档的相关性进行评分,我们能够优先考虑用于生成响应的最佳信息。
这是一项强大的技术,可以显著提高 RAG 系统的质量。
08-RSE
我们一直专注于单个块,但有时最好的信息分散在多个连续的块中。相关段提取 (RSE) 解决了这个问题。
RSE不仅仅抓取前k个块,还尝试识别和提取相关文本的整个片段。
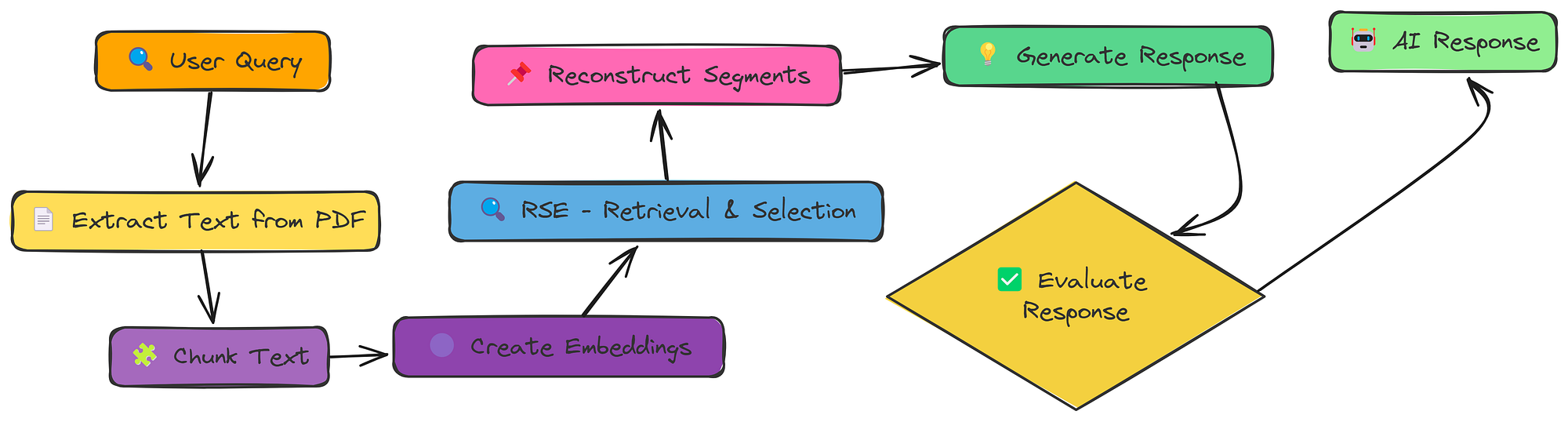
RSE(由Fareed Khan创建)
让我们看看如何在现有管道中实现这一点,我们使用已定义的函数RSE。我们正在添加一个函数调用 rag_with_rse,它接受 pdf_path 和 query 并返回响应。我们结合几个函数调用来执行 RSE.
# Run RAG with RSE
rse_result = rag_with_rse(pdf_path, query)
这一行代码做了很多事情!它:
- 处理文档(提取文本、分块、创建嵌入,全部在rag_with_rse内部处理)。
- 根据与查询和位置的相关性计算“块值”。
- 使用巧妙的算法来找到最佳的连续块段。
- 将这些片段组合成一个上下文。
- 根据该上下文生成响应。
现在来评价一下:
# Evaluate
evaluation_prompt = f"User Query: {query}\nAI Response:\n{rse_result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTPUT ###
However, the Response from Standard Retrieval includes ...
0.8 is the score I would assign to AI Response
而且...我们的得分已经达到了 0.8 左右!
通过关注相关文本的连续片段,RSE 为 LLM 提供了更连贯、更完整的背景,从而带来更准确、更全面的回应。
这表明我们如何选择和向 LLM 呈现信息与我们选择什么信息一样重要。
09-上下文压缩
我们一直在添加越来越多的背景信息、相邻的区块、生成的问题和整个片段。但有时,少即是多。
LLM 的上下文窗口有限,如果在其中填充不相关的信息可能会影响性能。
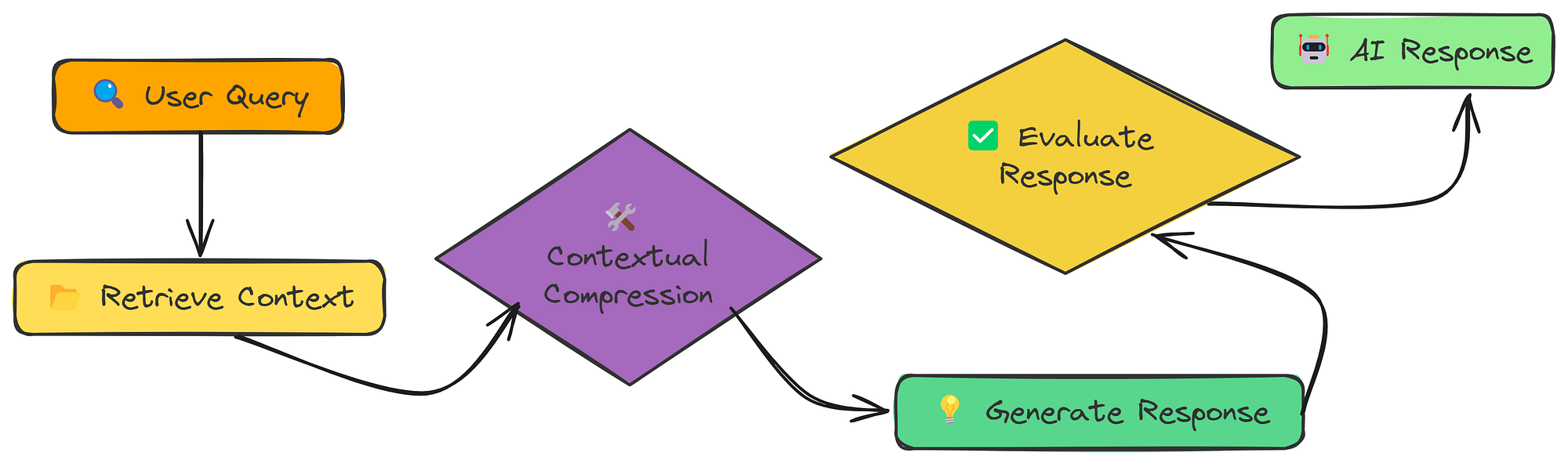
上下文压缩(由Fareed Khan创建)
上下文压缩(由Fareed Khan创建)
上下文压缩是一种选择性压缩。我们检索大量上下文,然后对其进行压缩,只保留与查询直接相关的部分。
这里的关键区别在于生成之前的**“上下文压缩”**步骤。我们不会改变检索到的内容,而是在将其传递给 LLM 之前对其进行改进。
我们在这里使用一个函数调用rag_with_compression,它接受query和其他参数并实现上下文压缩。在内部,它使用 LLM 分析检索到的块并仅提取与直接相关的句子或段落query。
让我们看看它的实际效果:
def rag_with_compression ( pdf_path, query, k= 10 , compression_type= "selective" , model= "meta-llama/Llama-3.2-3B-Instruct" ):
"""
带有上下文压缩的 RAG(检索增强生成)管道。
参数:
pdf_path(str):PDF 文档的路径。query
(str):用于检索的用户查询。k
(int):要检索的相关块数。默认值为 10。compression_type
(str):应用于检索到的块的压缩类型。默认值为“selective”。model
(str):用于生成响应的语言模型。默认值为“meta-llama/Llama-3.2-3B-Instruct”。
返回:
dict:包含查询、原始和压缩块、压缩统计数据和最终响应的字典。
"""
print ( f"\n=== RAG WITH COMPRESSION ===\nQuery: {query} | 压缩:{compression_type} " )
# 处理文档以提取、分块和嵌入文本
vector_store = process_document(pdf_path)
# 根据查询相似度检索前 k 个相关块
results = vector_store.similarity_search(create_embeddings(query), k=k)
removed_chunks = [r[ "text" ] for r in results]
# 对检索到的块应用压缩
compressed = batch_compress_chunks(retrieved_chunks, query, compression_type, model)
# 过滤掉空的压缩块;如果所有都是空的,则回退到原始
compressed_chunks, compression_ratios = zip ([(c, r) for c, r in compressed if c.strip()] or [(chunk, 0.0 ) for chunk in removed_chunks])
# 组合压缩块以形成用于生成响应的上下文
context = "\n\n---\n\n" .join(compressed_chunks)
# 使用压缩上下文生成响应 response
= generate_response(query, context, model)
print ( f"\n=== RESPONSE ===\n {response} " )
# 返回详细结果
return {
"query" : query,
"original_chunks" : removed_chunks,
"compressed_chunks" : compressed_chunks,
"compression_ratios" :压缩比,
“context_length_reduction”:f“ {总和(压缩率)/ len(压缩率):. 2 f}%”,
“响应”:响应
}
rag_with_compression 为不同的压缩类型提供了选项:
- **“选择性”:**只保留直接 相关的句子。
- **“摘要”:**创建针对查询的简短摘要。
- **“提取”:**仅提取包含答案的句子(非常严格!)。
现在,为了运行压缩,我们使用以下代码:
# Run RAG with contextual compression (using 'selective' mode)
compression_result = rag_with_compression(pdf_path, query, compression_type="selective")
# Evaluate.
evaluation_prompt = f"User Query: {query}\nAI Response:\n{compression_result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTPUT ###
Evaluation Score 0.75
这给了我们一个大约 0.75 的分数。
上下文压缩是一种强大的技术,因为它平衡了广度(初始检索获得广泛的信息)和焦点(压缩消除噪音)。
通过向 LLM 提供最相关的信息,我们通常可以获得更简洁、更准确的答案。
10-反馈回路
到目前为止,我们看到的所有技术都是“静态的”,它们不会从错误中吸取教训。反馈循环改变了这种情况。
这个想法很简单:
- 用户对 RAG 系统的响应提供反馈(例如,好/坏、相关/不相关)。
- 系统存储该反馈。
- 未来的检索将使用此反馈来改进。

反馈循环(由Fareed Khan创建)
我们可以使用函数调用来实现反馈循环full_rag_workflow。这是函数定义。
def full_rag_workflow ( pdf_path, query, feedback_data= None , feedback_file= "feedback_data.json" , fine_tune= False ):
"""
执行带有反馈集成的完整 RAG 工作流程以持续改进。
"""
# 步骤 1:如果未明确提供,则加载历史反馈以进行相关性调整
if feedback_data is None :
feedback_data = load_feedback_data(feedback_file)
print ( f"Loaded { len (feedback_data)} feedback entry from {feedback_file} " )
# 步骤 2:通过提取、分块和嵌入管道处理文档
chunks, vector_store = process_document(pdf_path)
# 步骤 3:通过合并高质量的过去交互来微调向量索引
# 这将从成功的问答对中创建增强的可检索内容
if fine_tune and feedback_data:
vector_store = fine_tune_index(vector_store, chunks, feedback_data)
# 步骤 4:使用反馈感知检索
# 注意:这取决于 rag_with_feedback_loop 函数,该函数应在其他地方定义
result = rag_with_feedback_loop(query, vector_store, feedback_data)
# 步骤 5:收集用户反馈以提高未来的性能
print ( “\n=== 您想对此回复提供反馈吗? ===" )
print ( "评价相关性(1-5,5 为最相关):" )
relevance = input ()
print ( "评价质量(1-5,5 为最优质):" )
quality = input ()
print ( "有任何评论吗?(可选,按 Enter 跳过)" )
comments = input ()
# 步骤 6:将反馈格式化为结构化数据
feedback = get_user_feedback(
query=query,
response=result[ "response" ],
relevance= int (relevance),
quality= int (quality),
comments=comments
)
# 步骤 7:保留反馈以实现持续的系统学习
store_feedback(feedback, feedback_file)
print ( "反馈已记录。谢谢!" )
return result
这个 full_rag_workflow 函数做了几件事:
- **加载现有反馈:**它检查 feedback_data.json 文件并加载任何以前的反馈。
- **运行 RAG 管道:**这部分与我们之前所做的类似。
- **征求反馈:**它提示用户对响应的相关性和质量进行评分。
- **存储反馈:**将反馈保存到feedback_data.json文件。
这种反馈如何真正用于改善检索的神奇之处更为复杂,并且发生在诸如 之类的函数中fine_tune_index(adjust_relevance_scores为简洁起见,此处未显示)。但关键思想是,好的反馈可以提高某些文档的相关性,而坏的反馈则会降低相关性。
让我们运行一个简化版本,假设我们没有任何现有的反馈:
# 我们没有之前的反馈,因此“fine_tune=False”
result = full_rag_workflow(pdf_path=pdf_path, query=query, fine_tune= False )
# 评估。evaluation_prompt
= f“用户查询:{query} \nAI 响应:\n {result[ 'response' ]} \nTrue 响应:{reference_answer} \n {evaluate_system_prompt} ”
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print (evaluation_response.choices[ 0 ].message.content)
### OUTPUT ###
评估分数为 0.7,因为......
我们看到分数在 0.7 左右!
这不是一个巨大的飞跃,这是意料之中的。反馈回路会随着时间的推移不断改进系统,并不断进行交互。本节仅演示该机制。
真正的力量来自于积累反馈并利用它来改进检索过程。这使得 RAG 系统能够根据收到的查询类型进行自适应和个性化。
11-自适应 RAG
我们探索了改进 RAG 的各种方法:更好地分块、添加上下文、转换查询、重新排名,甚至结合反馈。
自适应 Rag 工作流程(由Fareed Khan创建)
但如果最佳技术取决于所提问题的类型,该怎么办?这就是 Adaptive RAG 背后的想法。
我们在这里使用四种不同的策略:
- **事实策略:**注重检索精确的事实和数据。
- **分析策略:**旨在全面涵盖某个主题,探索不同的方面。
- **意见策略:**试图收集有关主观问题的不同观点。
- **语境策略:**结合用户特定的语境来定制检索。
让我们看看它是如何工作的。我们将使用一个名为的函数**rag_with_adaptive_retrieval**来处理整个过程:
def rag_with_adaptive_retrieval ( pdf_path, query, k= 4 , user_context= None ):
"""
使用自适应检索完成 RAG 管道。
"""
print ( "\n=== RAG WITH ADAPTIVE RETRIEVAL ===" )
print ( f"Query: {query} " )
# 处理文档以提取文本、对其进行分块并创建嵌入
chunks, vector_store = process_document(pdf_path)
# 对查询进行分类以确定其类型
query_type = classify_query(query)
print ( f"Query classified as: {query_type} " )
# 根据查询类型使用自适应检索策略检索文档
retrieved_docs = adaptive_retrieval(query, vector_store, k, user_context)
# 根据查询、检索到的文档和查询类型生成响应
response = generate_response(query, retained_docs, query_type)
# 编译结果放入字典中
result = {
"query": query,
"query_type": query_type,
"retrieved_documents": retrieved_docs,
"response": response
}
print("\n=== RESPONSE ===")
print(response)
return result
classify_query它首先使用由其他辅助函数定义的函数对查询进行分类。
根据识别的类型,选择并执行适当的专门检索策略(factual_retrieval_strategy、analytical_retrieval_strategy、opinion_retrieval_strategy或contextual_retrieval_strategy)。
最后,使用generate_response检索到的文档生成响应。
该函数返回一个包含结果的字典,包括query、query type、retrieved documents和generated response。
让我们使用这个函数并评估它:
# 运行自适应 RAG 管道
result = rag_with_adaptive_retrieval(pdf_path, query)
# Evaluate.
evaluation_prompt = f"User Query: {query}\nAI Response:\n{result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTPUT ###
Evaluation score is 0.86
这次我们取得了0.856左右的分数。
通过调整我们的检索策略以适应特定类型的查询,我们可以获得比一刀切方法更好的结果。这凸显了了解用户意图并相应地定制 RAG 系统的重要性。
自适应 RAG 不是一个固定的程序,而是一个框架,它能够根据查询选择最佳策略。
12-Self-RAG
到目前为止,我们的 RAG 系统基本上是被动的。它们接受查询、检索信息并生成响应。Self-RAG 采用了不同的方法:它是主动的和反思性的。
它不仅仅是检索和生成,它还会思考是否检索、检索什么以及如何使用检索到的信息。
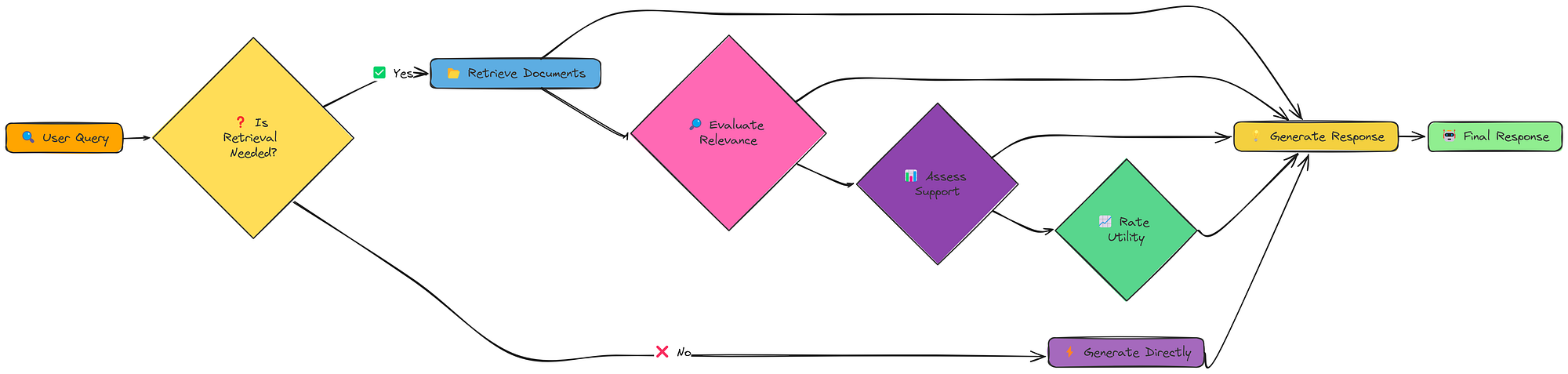
自我 RAG 工作流程(由Fareed Khan创建)
这些**“反射”**步骤使 Self-RAG 比传统 RAG 更具动态性和适应性。它可以决定:
- 完全跳过检索。
- 使用不同的策略进行多次检索。
- 丢弃不相关的信息。
- 优先考虑有良好支持且有用的信息。
Self-RAG 的核心在于它能够生成“反射标记”。这些是模型用来推理自身过程的特殊标记。例如,它对retrieval_needed、relevance、support_rating和utility_ratings使用不同的标记。
模型使用这些标记的组合来决定何时必须检索、何时不必检索,以及 LLM 应在什么基础上生成最终响应。
首先,决定是否需要检索:
def determine_if_retrieval_needed ( query ):
"""
(说明性示例 - 并非完全功能)
确定给定查询是否需要检索。
"""
system_prompt = """您是 AI 助手,可确定是否需要检索来回答查询。
对于事实问题、具体信息请求或有关事件、人物或概念的问题,请回答“是”。
对于意见、假设情景或具有常识的简单查询,请回答“否”。
仅回答“是”或“否”。"""
user_prompt = f"查询:{query} \n\n是否需要检索才能准确回答此查询?"
response = client.chat.completions.create(
model= "meta-llama/Llama-3.2-3B-Instruct" ,
messages=[
{ "role" : "system" , "content" : system_prompt},
{ "role" : "user" , "content" : user_prompt}
],
temperature= 0
)
answer = response.choices[ 0 ].message.content.strip().lower()
return "yes" in answer
此determine_if_retrieval_needed功能(再次简化)使用 LLM 来判断是否需要外部信息。
- **对于像“法国的首都是哪里?”**这样的事实问题,它可能会返回
False(LLM可能已经知道这一点)。 - **对于“写一首诗...”**这样的创造性任务,它也可能会返回
False - 但对于更复杂或更小众的查询,它会返回
True。
以下是相关性评估的一个简化示例:
def assess_relevance ( query, context ):
"""
(说明性示例 - 并非完全功能)
评估上下文与查询的相关性。
"""
system_prompt = """您是 AI 助手。确定文档是否与查询相关。
仅用“相关”或“不相关”回答。"""
user_prompt = f"""查询:{query}
文档内容:
{context[: 500 ]} ... [truncated]
此文档是否与查询相关?仅用“相关”或“不相关”回答。
"""
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-3B-Instruct",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
],
temperature=0
)
answer = response.choices[0].message.content.strip().lower()
return answer
该evaluate_relevance函数(再次简化)使用 LLM 来判断检索到的文档是否与 相关query。
这使得Self-RAG能够在生成响应之前过滤掉不相关的文档。
最后,我们可以使用以下方法调用:
# 我们可以调用 `self_rag` 函数进行自我整理,它会自动
# 决定何时检索,何时不检索。result
result = self_rag(query, vector_store)
print(result["response"])
### OUTPUT ###
Evaluation score for the AI Response is 0.65
我们这里得到的分数是 0.6。
这反映了以下事实:
- Self-RAG 具有巨大的潜力,但全面实施起来很复杂。
- 甚至我们展示的“是否需要检索?”步骤有时也可能是错误的。
- 我们还没有展示完整的“反思”过程,所以我们不能要求获得更高的分数。
关键点在于,Self-RAG 旨在让 RAG 系统更加智能、更具适应性。这是向能够推理自身知识和检索需求的 LLM 迈出的一步。
13-知识图谱
到目前为止,我们的 RAG 系统将文档视为独立块的集合。但如果信息是相互关联的,该怎么办?如果理解一个概念需要理解相关概念,该怎么办?这就是 Graph RAG 的作用所在。
Graph RAG 不是以扁平的块列表形式组织信息,而是以知识图谱的形式组织信息。可以将其想象成一个网络:
- 节点:表示概念、实体或信息片段(如我们的文本块)。
- 边:表示这些节点之间的关系。
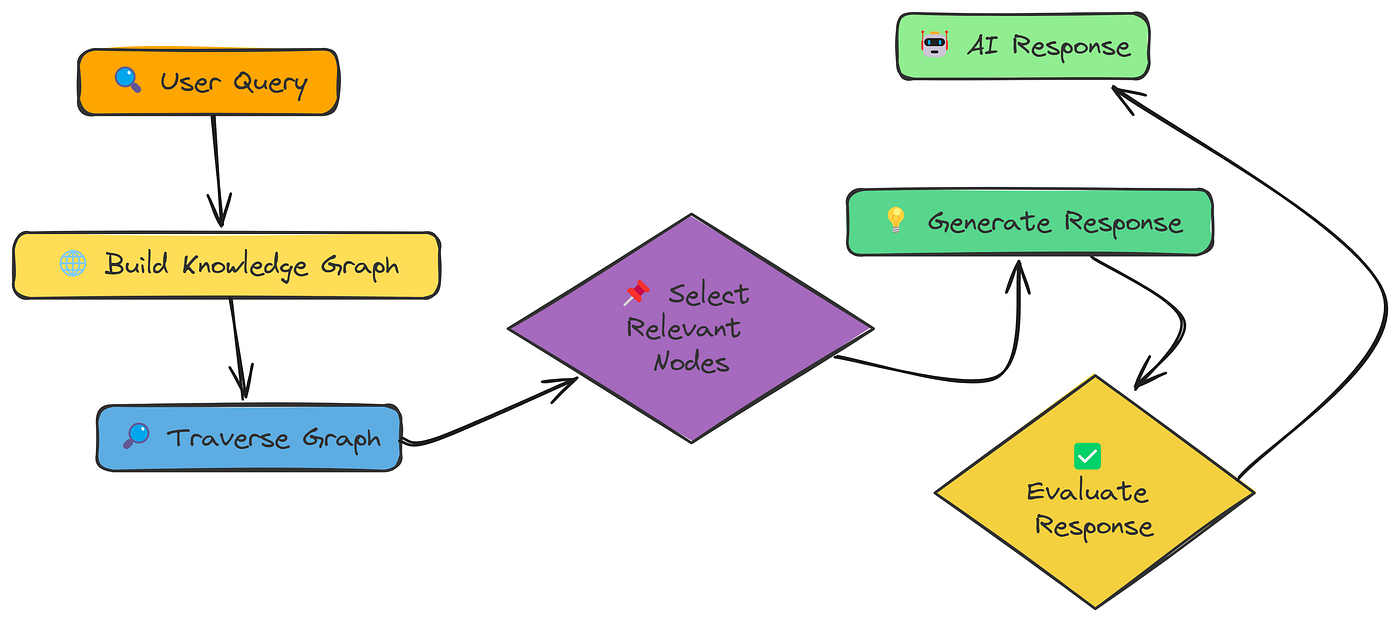
知识图谱工作流程(由Fareed Khan创建)
核心思想是,通过遍历该图,我们不仅可以找到直接相关的信息,还可以找到提供关键背景的间接相关信息。
让我们看一些核心步骤如何工作的简化代码:首先,构建知识图谱:
def build_knowledge_graph ( chunks ):
"""
使用嵌入和概念提取从文本块构建知识图谱。
参数:
chunks(字典列表):文本块列表,每个块包含一个“text”字段。
返回:
tuple:(以节点为文本块的图,嵌入列表)
"""
graph, texts = nx.Graph(), [c[ "text" ] for c in chunks]
embeddings = create_embeddings(texts) # 计算嵌入
# 添加带有提取概念和嵌入的节点
for i, (chunk, emb) in enumerate ( zip (chunks, embeddings)):
graph.add_node(i, text=chunk[ "text" ], ideas := extract_concepts(chunk[ "text" ]), embedding=emb)
# 根据共享概念和嵌入相似性创建边
for i, j in ((i, j) for i in range(len(chunks)) for j in range(i + 1, len(chunks))):
if shared_concepts := set(graph.nodes[i]["concepts"]) & set(graph.nodes[j]["concepts"]):
sim = np.dot(embeddings[i], embeddings[j]) / (np.linalg.norm(embeddings[i]) np.linalg.norm(embeddings[j]))
weight = 0.7 * sim + 0.3 * (len(shared_concepts) / min(len(graph.nodes[i]["concepts"]), len(graph.nodes[j]["concepts"])))
if weight > 0.6:
graph.add_edge(i, j, weight=weight, similarity=sim, shared_concepts=list(shared_concepts))
print(f"Graph built: {graph.number_of_nodes()} nodes, {graph.number_of_edges()} edges")
return graph, embeddings
它接受 a query、agraph和embeddings,并返回相关节点列表和遍历路径。
最后,我们有graph_rag_pipeline使用这两个函数的:
def graph_rag_pipeline(pdf_path, query, chunk_size=1000, chunk_overlap=200, top_k=3):
"""
从文档到答案的完整 Graph RAG 管道。
"""
# 从 PDF 文档中提取文本
text = extract_text_from_pdf(pdf_path)
# 将提取的文本拆分为重叠块
chunks = chunk_text(text, chunk_size, chunk_overlap)
# 从文本块构建知识图谱
graph, embeddings = build_knowledge_graph(chunks)
# 遍历知识图谱以查找与查询相关的信息
related_chunks, traversal_path = traverse_graph(query, graph, embeddings, top_k)
# 根据查询和相关块生成响应
response = generate_response(query, related_chunks)
# 返回查询、响应、相关块、遍历路径和图形
return {
"query": query,
"response": response,
"relevant_chunks": relevant_chunks,
"traversal_path": traversal_path,
"graph": graph
}
让我们使用它来生成响应:
# 执行 Graph RAG 管道来处理文档并回答查询
results = graph_rag_pipeline(pdf_path, query)
# Evaluate.
evaluation_prompt = f"User Query: {query}\nAI Response:\n{results['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTPUT
0.78
我们的得分是0.78左右。
Graph RAG 的表现并不优于更简单的方法,但它可以捕捉信息片段之间的关系,而不仅仅是各个片段本身。
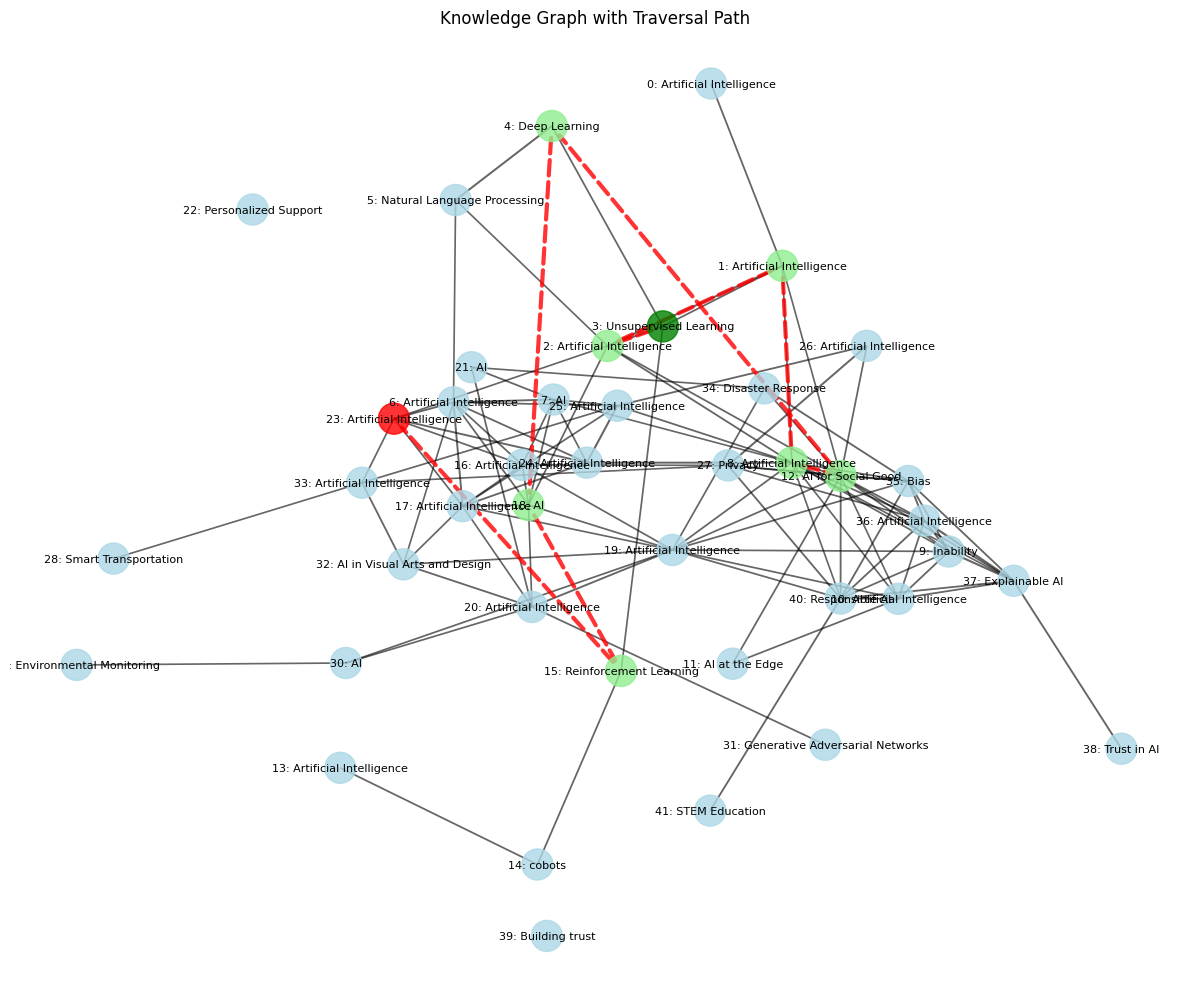
KG 关于我们的验证 pdf (由Fareed Khan创建)
这对于需要理解概念之间联系的复杂查询尤其有用。
14-层次索引
我们探索了各种改进 RAG 的方法:更好的分块、上下文丰富、查询转换、重新排序,甚至基于图形的检索。但这存在一个根本性的权衡:
- 小块:适合精确匹配,但会丢失上下文。
- 大块:保留上下文,但会导致检索相关性降低。
分层索引提供了一种解决方案:我们创建两个级别的表示:
- 摘要:对文档主要内容的简要概述。
- 详细块:这些部分内的较小块。
分层索引工作流程(由Fareed Khan创建)
- 首先,搜索摘要:这可以快速缩小文档的相关部分。
- 然后,仅在这些部分内搜索详细块:这提供了小块的精度,同时保持了较大部分的上下文。
让我们通过函数调用来看一下这个操作hierarchical_rag:
def hierarchical_rag(query, pdf_path, chunk_size=1000, chunk_overlap=200,
k_summaries=3, k_chunks=5, regenerate=False):
"""
完成分层检索增强生成 (RAG) 管道。
参数:
query (str):用户查询。pdf_path
(str):PDF 文档的路径。chunk_size
(int):要处理的文本块的大小。chunk_overlap
(int):连续块之间的重叠。k_summaries
(int):要检索的顶级摘要的数量。k_chunks
(int):每个摘要要检索的详细块数。regenerate
(bool):是否重新处理文档。
返回:
dict:包含查询、生成的响应、检索到的块
以及摘要和详细块的计数。
"""
# 定义用于缓存摘要和详细向量存储的文件名
summary_store_file = f"{os.path.basename(pdf_path)}_summary_store.pkl"
detailed_store_file = f"{os.path.basename(pdf_path)}_detailed_store.pkl"
# 如果需要重新生成或缓存文件丢失,则处理文档,
if regenerate or not os.path.exists(summary_store_file) or not os.path.exists(detailed_store_file):
print("Processing document and creating vector stores...")
summary_store, detailed_store = process_document_hierarchically(pdf_path, chunk_size, chunk_overlap)
# Save processed stores for future use
with open(summary_store_file, 'wb') as f:
pickle.dump(summary_store, f)
with open(detailed_store_file, 'wb') as f:
pickle.dump(detailed_store, f)
else:
# Load existing vector stores from cache
print("Loading existing vector stores...")
with open(summary_store_file, 'rb') as f:
summary_store = pickle.load(f)
with open(detailed_store_file, 'rb') as f:
detailed_store = pickle.load(f)
# 使用分层搜索检索相关块
retrieved_chunks = retrieve_hierarchically(query, summary_store, detailed_store, k_summaries, k_chunks)
# 根据检索到的块生成响应
response = generate_response(query, retrieved_chunks)
# 返回带有元数据的结果
return {
"query": query,
"response": response,
"retrieved_chunks": retrieved_chunks,
"summary_count": len(summary_store.texts),
"detailed_count": len(detailed_store.texts)
}
此hierarchical_rag函数处理两阶段检索过程:
- 首先,它搜索
summary_store以找到最相关的摘要。 - 然后,它会搜索
detailed_store运行分层 RAG 管道,但只在属于顶部摘要的块内进行搜索。这比搜索所有详细块要高效得多。
该函数还有一个regenerate参数,用于创建新的向量存储或使用现有的向量存储。
让我们用它来回答我们的查询并进行评估:
# Run the hierarchical RAG pipeline
result = hierarchical_rag(query, pdf_path)
我们检索并生成响应。最后,让我们看看评估分数:
# Evaluate.
evaluation_prompt = f"User Query: {query}\nAI Response:\n{result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTPUT
0.84
我们的分数是 0.84
分层检索提供了迄今为止最好的分数。
我们获得了搜索摘要的速度和搜索较小块的精度,以及通过了解每个块属于哪个部分而获得的附加上下文。这就是为什么它通常是表现最佳的 RAG 策略。
15-HyDE
到目前为止,我们一直直接嵌入用户的查询或其转换版本。HyDE(假设文档嵌入)采用了不同的方法。它不是嵌入查询,而是嵌入回答查询的假设文档。
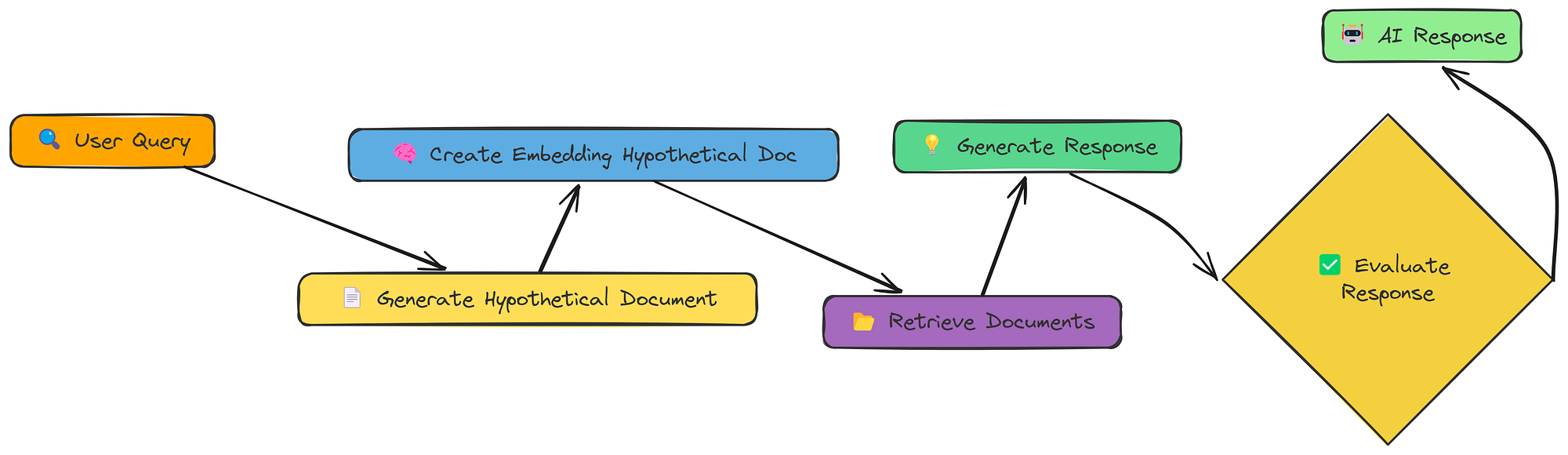
HyDE 工作流程(由Fareed Khan创建)
流程如下:
- 生成假设文档:可以使用 LLM 创建一个回答查询的文档(如果存在)。
- 嵌入假设文档:创建此假设而不是文档的嵌入,原始查询。
- 检索:查找与嵌入相似的文档。
- 生成:使用文档(而不是假设的文档!)来回答查询。
其理念是,完整文档(即使是假设文档)比简短查询具有更丰富的语义表示。这有助于弥合查询和嵌入空间中的文档之间的差距。
让我们看看它是如何工作的。首先,我们需要一个函数来生成那个假设的文档。
我们generate_hypothetical_document这样做:
def generate_hypothetical_document(query, desired_length=1000):
"""
生成一个假设文档来回答查询。
"""
"""您是专家文档创建者。
给定一个问题,生成一份详细的文档来直接回答这个问题。
文档长度应约为{desired_length}个字符,并提供对该问题的深入、
翔实的答案。写作时要像这份文件来自
该主题的权威来源一样。包括具体的细节、事实和解释。
不要提到这是一份假设文件 - 只需直接写出内容即可。"""
# 定义系统提示以指导模型如何生成文档
system_prompt = f"""You are an expert document creator.
Given a question, generate a detailed document that would directly answer this question.
The document should be approximately {desired_length} characters long and provide an in-depth,
informative answer to the question. Write as if this document is from an authoritative source
on the subject. Include specific details, facts, and explanations.
Do not mention that this is a hypothetical document - just write the content directly."""
# 使用查询定义用户提示
user_prompt = f"Question: {query}\n\nGenerate a document that fully answers this question:"
# 向 OpenAI API 发出请求以生成假设文档
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-3B-Instruct", # Specify the model to use
messages=[
{"role": "system", "content": system_prompt}, # System message to guide the assistant
{"role": "user", "content": user_prompt} # User message with the query
],
temperature=0.1 # Set the temperature for response generation
)
# 返回生成的文档内容
return response.choices[0].message.content
该函数接受查询并使用 LLM 来创建回答该查询的文档。
现在,让我们将其全部放在 hyde_rag 函数中:
def hyde_rag(query, vector_store, k=5, should_generate_response=True):
"""
使用假设文档嵌入执行 RAG。
"""
print(f"\n=== Processing query with HyDE: {query} ===\n")
# 步骤 1:生成一个回答查询的假设文档
print("Generating hypothetical document...")
hypothetical_doc = generate_hypothetical_document(query)
print(f"Generated hypothetical document of {len(hypothetical_doc)} characters")
# 步骤 2:为假设文档创建嵌入
print("Creating embedding for hypothetical document...")
hypothetical_embedding = create_embeddings([hypothetical_doc])[0]
# 步骤 3:根据假设文档检索相似的块
print(f"Retrieving {k} most similar chunks...")
retrieved_chunks = vector_store.similarity_search(hypothetical_embedding, k=k)
# 准备结果字典
results = {
"query": query,
"hypothetical_document": hypothetical_doc,
"retrieved_chunks": retrieved_chunks
}
# 步骤 4:如果要求,生成响应
if should_generate_response:
print("Generating final response...")
response = generate_response(query, retrieved_chunks)
results["response"] = response
return results
hyde_rag 函数现在:
- 生成假设文档。
- 创建该文档的嵌入(不是查询!)。
- 使用嵌入进行检索。
- 像以前一样生成响应。
让我们运行它并查看生成的响应:
# Run HyDE RAG
hyde_result = hyde_rag(query, vector_store)
# Evaluate.
evaluation_prompt = f"User Query: {query}\nAI Response:\n{hyde_result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTPUT
0.5
我们的评估分数在0.5左右。
HyDE 的想法很聪明,但并不总是效果更好。在这种情况下,假设的文档可能与我们实际的文档集合的方向略有不同,导致检索结果相关性较低。
这里的关键教训是,没有单一的“最佳” RAG 技术。不同的方法对不同的查询和不同的数据效果更好。
16-融合
我们已经看到,不同的检索方法各有千秋。向量搜索擅长语义相似性,而关键字搜索擅长查找精确匹配。如果我们能将它们结合起来会怎么样?这就是 Fusion RAG 背后的想法。

Fusion RAG 工作流程(由Fareed Khan创建)
Fusion RAG不会选择一种检索方法,而是同时执行两种方法,然后合并并重新排列结果。这使我们能够同时捕获语义含义和精确的关键字匹配。
我们实现的核心是 fusion_retrieval 函数。此函数执行基于向量和基于 BM25 的检索,对每个分数进行规范化,使用加权公式将它们组合起来,然后根据组合分数对文档进行排名。
以下是融合检索的函数:
import numpy as np
def fusion_retrieval(query, chunks, vector_store, bm25_index, k=5, alpha=0.5):
"""通过结合基于向量和 BM25 的搜索结果执行融合检索。"""
# 为查询生成嵌入
query_embedding = create_embeddings(query)
# 执行向量搜索并将结果存储在字典中(索引 -> 相似度得分)
vector_results = {
r[ "metadata" ][ "index" ]: r[ "similarity" ]
for r in vector_store.similarity_search_with_scores(query_embedding, len (chunks))
}
# 执行 BM25 搜索并将结果存储在字典中(索引 -> BM25 得分)
bm25_results = {
r[ "metadata" ][ "index" ]: r[ "bm25_score" ]
for r in bm25_search(bm25_index, chunks, query, len (chunks))
}
# 从向量存储中检索所有文档
all_docs = vector_store.get_all_documents()
# 使用向量和 BM25 分数的加权和计算每个文档的综合分数
scores = [
(i, alpha * vector_results.get(i, 0 ) + ( 1 - alpha) * bm25_results.get(i, 0 ))
for i in range ( len (all_docs))
]
# 按综合分数降序对文档进行排序,并保留前 k 个结果
top_docs = sorted (scores, key= lambda x: x[ 1 ], reverse= True )[:k]
# 返回包含文本、元数据和综合分数的前 k 个文档
return [
{"text": all_docs[i]["text"], "metadata": all_docs[i]["metadata"], "score": s}
for i, s in top_docs
]
它结合了两种方法的优点:
- 向量搜索:使用我们现有的 create_embeddings 和 SimpleVectorStore 实现语义相似性。
- BM25 搜索:使用 BM25 算法(一种标准信息检索技术)实现基于关键字的搜索。
- 分数组合:将两种方法的分数结合起来,给出一个统一的排名。
让我们运行完整的管道并生成响应:
# 首先,处理文档以创建块、向量存储和 BM25 索引
chunks,vector_store,bm25_index = process_document(pdf_path)
# 使用融合检索运行 RAG
fusion_result = answer_with_fusion_rag(query,chunks,vector_store,bm25_index)
print (fusion_result[ "response" ])
# 评估。evaluate_prompt
= f"User Query: {query} \nAI Response:\n {fusion_result[ 'response' ]} \nTrue Response: {reference_answer} \n {evaluate_system_prompt} "
evaluate_response =generate_response(evaluate_system_prompt,evaluation_prompt)
print (evaluation_response.choices[ 0 ].message.content)
### OUTPUT
Evaluation score for AI Response is 0.83
最终得分为0.83。
Fusion RAG 通常能给我们带来显著的提升,因为它结合了不同检索方法的优势。
这就像有两个专家一起工作,一个擅长理解查询的含义,另一个擅长找到完全匹配。
17-多模型
到目前为止,我们只处理文本。但很多信息都被困在图像、图表和示意图中。多模态 RAG 旨在解锁这些信息,并利用它们来改进我们的响应。
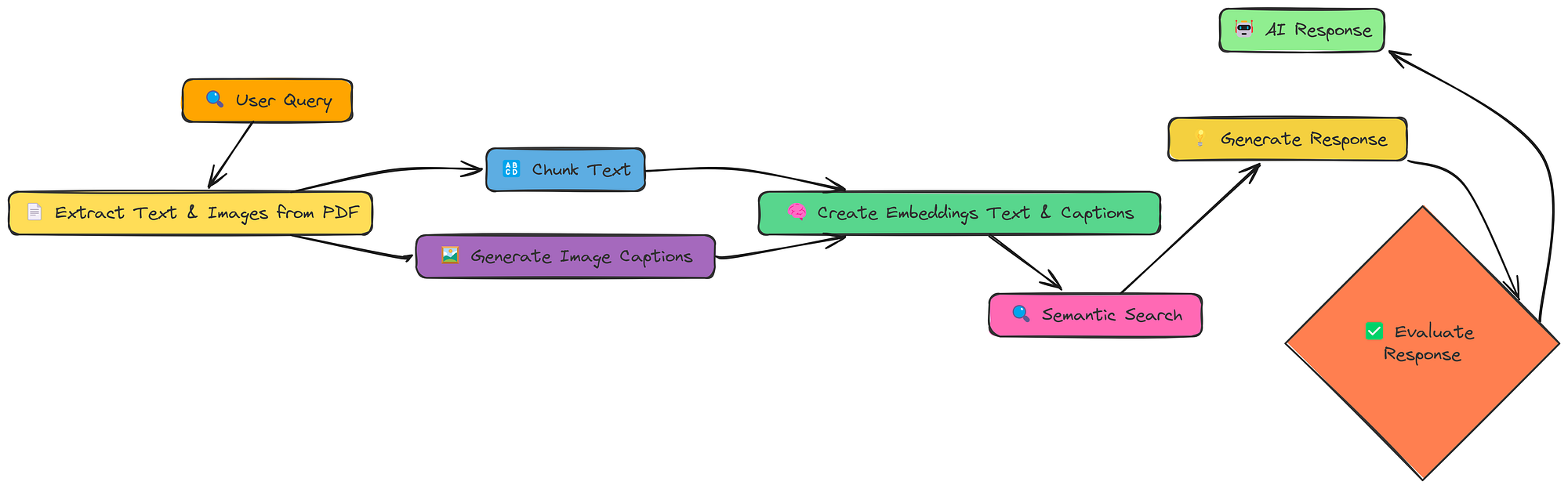
多模型工作流(由Fareed Khan创建)
这里的关键变化是:
- 提取文本和图像:我们从 PDF 中提取文本和
- 生成图像标题:我们使用 LLM(具体来说,具有**视觉功能的模型)为每个图像生成文本描述(标题)。
- 创建嵌入(文本和标题):我们为文本块标题创建嵌入。
- 嵌入模型:在此笔记本中,我们使用 BAAI/bge-en-icl 嵌入模型。
- LLM 模型:为了生成响应和图像标题,我们将使用 llava-hf/llava-1.5–7b-hf 模型。
这样,我们的向量存储就包含文本和视觉信息,并且我们可以跨两种模式进行搜索。
这里我们定义process_document函数:
def process_document(pdf_path, chunk_size=1000, chunk_overlap=200):
"""
为多模态 RAG 处理文档。
"""
# 为提取的图像创建目录
image_dir = "extracted_images"
os.makedirs(image_dir, exist_ok= True )
# 从 PDF 中提取文本和图像
text_data, image_paths = extract_content_from_pdf(pdf_path, image_dir)
# 对提取的文本进行分
块 chunked_text = chunk_text(text_data, chunk_size, chunk_overlap)
# 处理提取的图像以生成标题
image_data = process_images(image_paths)
# 组合所有内容项(文本块和图像标题)
all_items = chunked_text + image_data
# 提取用于嵌入的内容
contents = [item[ "content" ] for item in all_items]
# 为所有内容创建嵌入
print ( "Creating embeddings for all content..." )
embeddings = create_embeddings(contents)
# 构建向量存储并添加带有嵌入的项目
vector_store = MultiModalVectorStore()
vector_store.add_items(all_items, embeddings)
# 准备包含文本块和图像标题计数的文档信息
doc_info = {
“text_count” : len (chunked_text),
“image_count” : len (image_data),
“total_items” : len (all_items),
}
# 打印添加项目的摘要
print(f"Added {len(all_items)} items to vector store ({len(chunked_text)} text chunks, {len(image_data)} image captions)")
# 返回向量存储和文档信息
return vector_store, doc_info
该函数处理图像提取和字幕以及的创建MultiModalVectorStore。
我们假设图像字幕的效果相当好。(在实际场景中,您需要仔细评估字幕的质量)。
现在,让我们通过查询将所有内容整合在一起:
# 处理文档以创建向量存储。我们为此创建了一个新的 PDF
pdf_path = "data/attention_is_all_you_need.pdf"
vector_store, doc_info = process_document(pdf_path)
# 运行多模态 RAG 管道。这与之前非常相似!
result = query_multimodal_rag(query,vector_store)
# 评估。evaluation_prompt
evaluation_prompt = f"User Query: {query}\nAI Response:\n{result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTPUT
0.79
我们的得分约为 0.79。
多模态 RAG 具有非常强大的潜力,尤其是在图像包含关键信息的文档中。然而,它目前的表现还不及我们目前所知的其他技术。
18-Crag
到目前为止,我们的 RAG 系统相对被动。它们检索信息并生成响应。但是,如果检索到的信息不好怎么办?如果信息不相关、不完整,甚至自相矛盾怎么办?矫正 RAG(CRAG)可以正面解决这个问题。
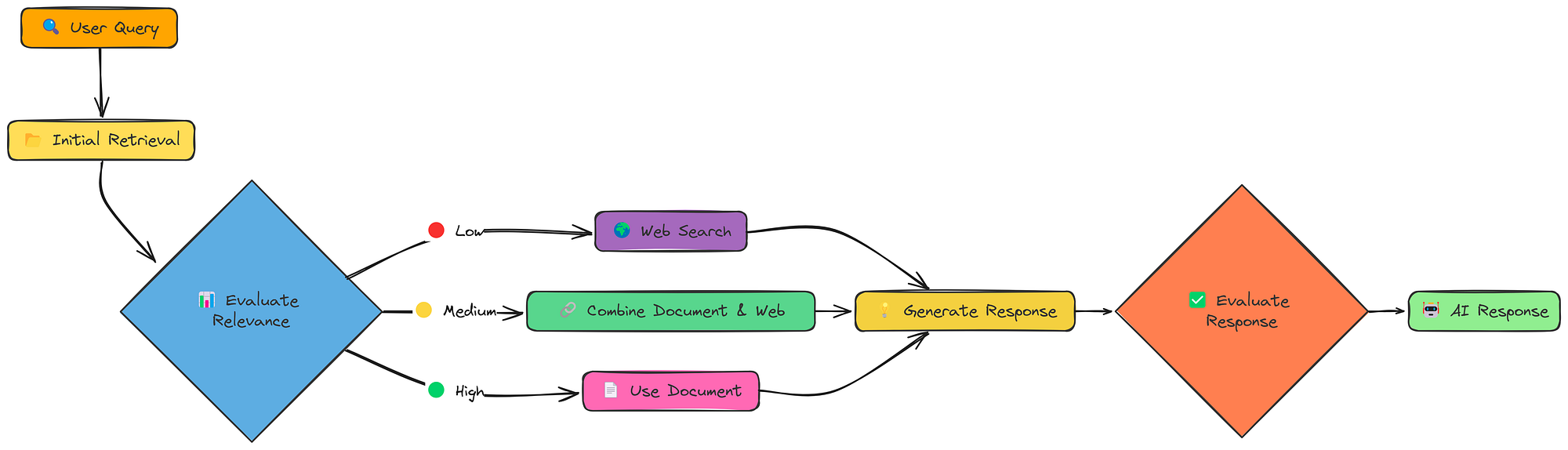
CRAG 工作流程(由Fareed Khan创建)
CRAG 增加了一个关键步骤:评估。初始检索之后,它会检查检索到的文档的相关性。而且,至关重要的是,它会根据评估结果制定不同的策略:
- 高相关性:如果检索到的文档良好,则照常进行。
- 相关性低:如果检索到的文档不好,则返回网络搜索!
- 中等相关性:如果文档没有问题,则结合文档和网络的信息。
这种“纠正”机制使 CRAG 比标准 RAG 更加稳健。它并非只是期盼最好的结果,而是主动检查并进行调整。
让我们看看这在实践中是如何运作的。我们将使用一个函数rag_with_compression来调用它。
# Run CRAG
crag_result = rag_with_compression(pdf_path, query, compression_type="selective")
这个单一函数调用做了很多事情:
- 初始检索:照常检索文档。
- 相关性评估:对每个文档与查询的相关性进行评分。
- 决策:决定是否使用文档、进行网络搜索或两者结合。
- 响应生成:使用所选的知识源生成响应。
和往常一样,评价如下:
# Evaluate.
evaluation_prompt = f"User Query: {query}\nAI Response:\n{crag_result['response']}\nTrue Response: {reference_answer}\n{evaluate_system_prompt}"
evaluation_response = generate_response(evaluate_system_prompt, evaluation_prompt)
print(evaluation_response.choices[0].message.content)
### OUTPUT ###
0.824
我们的目标分数是 0.824 左右。
CRAG检测和纠正检索失败的能力使其比标准 RAG 更加可靠。
通过在必要时动态切换到网络搜索,它可以处理更广泛的查询并避免陷入不相关或不充分的信息。
这种“自我纠正”能力是迈向更强大、更值得信赖的 RAG 系统的重要一步。
结论
通过对18种RAG技术的全面测试与比较,我们可以得出以下关键结论:
自适应RAG(Adaptive RAG)以0.86的评分成为最佳技术,其动态切换检索策略的能力使其在处理各类查询时表现出色
分层索引(0.84)、融合RAG(0.83)和CRAG(0.824)紧随其后,也展现了良好的性能
简单RAG虽然实现容易,但效果有限,需要结合更先进的技术才能满足复杂应用需求
选择合适的RAG技术应根据具体应用场景、数据特性和性能需求综合考虑
这些技术的实现代码都可以在GitHub仓库中找到,为开发者提供了宝贵的学习和实践资源。
经过测试的 18 种 RAG 技术代表了提高检索质量的多种方法,从简单的分块策略到自适应 RAG 等高级方法。
虽然简单 RAG 提供了基线,但分层索引(0.84)、融合(0.83)和 CRAG(0.824)等更复杂的方法通过解决检索挑战的不同方面,表现明显优于它。
自适应 RAG 通过根据查询类型智能地选择检索策略而成为最佳表现者(0.86),这表明具有上下文感知能力的灵活系统能够针对各种信息需求提供最佳结果。