- Published on
Chrome DevTools MCP 实战指南:浏览器自动化解决方案
- Authors

- Name
- Shoukai Huang

快速导航本篇内容:
1. Chrome 开发者工具 MCP 介绍
Chrome DevTools MCP(Model Context Protocol)是一个专业的浏览器自动化解决方案,它为 AI 编程助手(如 Gemini、Claude、Cursor 或 Copilot)提供了对实时 Chrome 浏览器的完整控制能力。作为标准化的 MCP 服务器实现,该工具使 AI 编码助手能够深度集成 Chrome DevTools 的全部功能,实现高可靠性的浏览器自动化、深度调试分析和全面的性能监控。
核心功能特性
性能分析与监控
- 利用 Chrome DevTools 的原生性能分析引擎,记录详细的执行轨迹
- 提供可操作的性能洞察和优化建议
- 支持 Core Web Vitals 指标的实时监测和分析
高级调试能力
- 全面的网络请求分析,包括请求/响应详情、时序分析
- 高质量屏幕截图捕获,支持全页面和元素级别截图
- 完整的浏览器控制台日志监控和错误追踪
智能自动化操作
- 基于 Puppeteer 引擎的可靠浏览器操作自动化
- 智能等待机制,确保操作的准确性和稳定性
- 支持复杂的用户交互场景模拟
MCP 客户端集成配置
要在您的 MCP 客户端中集成 Chrome DevTools MCP 服务器,请在配置文件中添加以下标准化配置:
{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": ["-y", "chrome-devtools-mcp@latest"]
}
}
}
配置说明:
- 使用
chrome-devtools-mcp@latest确保始终获取最新版本的功能更新和安全补丁 npx -y参数实现自动确认安装,简化部署流程- 该配置支持所有主流 MCP 客户端的标准集成方式
Trae AI 集成案例
以下演示展示了 Trae AI 如何通过 Chrome DevTools MCP 实现智能化的浏览器操作:
操作流程演示:
通过以下简洁的自然语言指令,即可实现复杂的浏览器自动化任务:
使用 chrome mcp 工具,
1. 打开 www.baidu.com
2. 搜索 ApFramework.com
3. 点击第一个链接
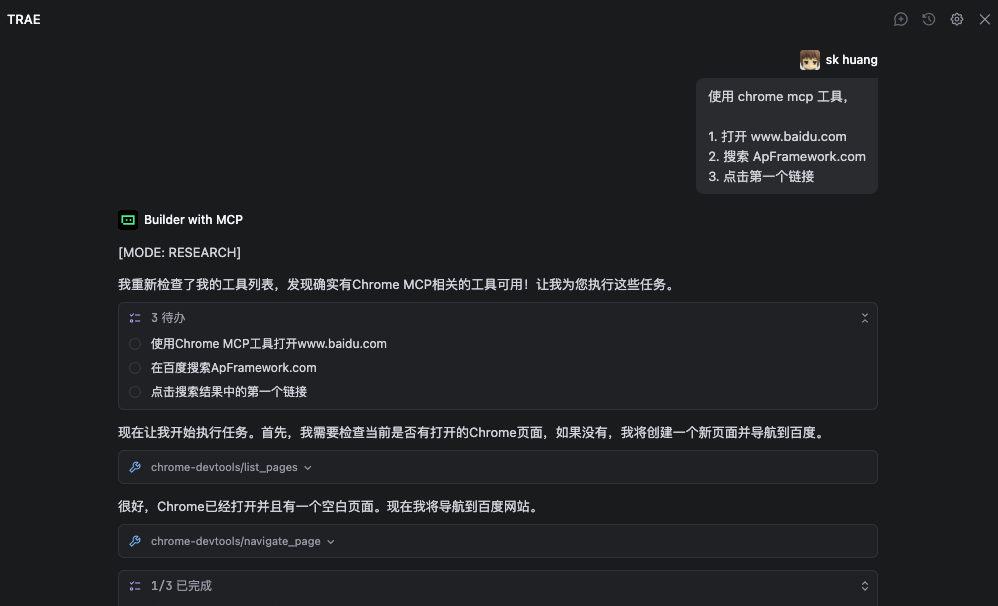
技术实现原理:
Trae AI 通过 MCP 协议与 Chrome DevTools 进行通信,利用多轮对话机制精确理解用户意图,并将复杂的浏览器操作分解为一系列原子化的 DevTools 命令。整个过程实现了从自然语言到浏览器操作的无缝转换,大幅提升了自动化任务的执行效率和准确性。
2. Chrome DevTools MCP 程序集成实践
开发环境配置
系统依赖要求
在开始集成之前,请确保您的开发环境满足以下要求:
- Node.js 运行时环境:Chrome DevTools MCP 依赖 Node.js 生态系统
- Python 开发环境:本示例使用 Python 进行 MCP 客户端开发
- Chrome 浏览器:需要支持远程调试协议的 Chrome 实例
项目初始化与依赖安装
使用现代 Python 包管理工具 uv 快速搭建开发环境:
# 创建新项目并初始化虚拟环境
uv init chrome-devtools-mcp-samples
cd chrome-devtools-mcp-samples
# 激活虚拟环境
source .venv/bin/activate
# 安装核心依赖包
uv add python-dotenv langchain-deepseek langgraph langchain langchain-mcp-adapters
环境变量配置
创建 .env 文件并配置必要的 API 密钥:
# DeepSeek API 配置(或其他兼容的 LLM 服务)
DEEPSEEK_API_KEY=your_api_key_here
# 可选:其他 LLM 服务配置
QWEN_API_KEY=your_qwen_api_key
QWEN_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
安全提示: 请确保将 .env 文件添加到 .gitignore 中,避免敏感信息泄露。
核心技术实现
MCP 服务器连接配置
为了避免浏览器实例重复创建的问题,推荐使用持久化连接配置:
{
"command": "npx",
"args": [
"-y",
"chrome-devtools-mcp@latest",
"--browserUrl=http://127.0.0.1:9222"
],
"transport": "stdio"
}
配置要点:
--browserUrl参数指向预启动的 Chrome 实例,避免重复启动stdio传输方式确保稳定的进程间通信- 端口
9222是 Chrome 远程调试的标准端口
完整代码实现示例
以下是一个完整的 Chrome DevTools MCP 集成示例,展示了如何构建一个专业的浏览器自动化代理:
文件:chrome_devtools_langgraph.py
"""
LangGraph 与 Chrome DevTools MCP 集成示例
这个示例展示了如何使用 LangGraph 调用 chrome-devtools-mcp 服务器
来实现浏览器自动化任务。
"""
from langchain_mcp_adapters.client import MultiServerMCPClient
from langchain.chat_models import init_chat_model
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.prebuilt import ToolNode
import os
import asyncio
from dotenv import load_dotenv
# 加载.env文件中的环境变量
load_dotenv()
class ChromeDevToolsAgent:
"""Chrome DevTools 自动化代理"""
def __init__(self):
# 初始化模型
self.model = init_chat_model(
"qwen3-max", # 使用千问模型
model_provider="openai", # 使用 OpenAI 兼容接口
api_key=os.environ.get("QWEN_API_KEY"),
base_url=os.environ.get("QWEN_BASE_URL"),
# 优化模型参数
temperature=0.1, # 降低随机性,提高一致性
max_tokens=4096, # 增加输出长度
top_p=0.8, # 控制采样范围
frequency_penalty=0.1, # 减少重复
presence_penalty=0.1, # 鼓励多样性
)
print("✅ 大模型初始化完成")
# 为模型添加系统提示词,提升任务执行能力
self.system_prompt = """你是一个专业的浏览器自动化助手,具备以下能力:
1. 精确理解任务:仔细分析用户的每个步骤要求
2. 智能网页操作:能够准确识别页面元素并执行相应操作
3. 内容提取专家:擅长从网页中提取和整理有价值的信息
4. 逻辑推理:能够根据页面内容做出合理的判断和选择
## 重要的工具使用规则:
### 必须遵循的操作顺序:
1. 导航到页面后,必须先调用 `mcp_chrome__devtools_take_snapshot` 获取页面快照
2. 任何页面操作前,都要先调用 `mcp_chrome__devtools_take_snapshot` 确保有最新的页面状态
3. 点击或填写表单后,再次调用 `mcp_chrome__devtools_take_snapshot` 查看页面变化
### 工具调用流程:导航页面 → take_snapshot → 分析页面 → 执行操作 → take_snapshot → 继续下一步
### 错误处理:
- 如果遇到 "No snapshot found" 错误,立即调用 `mcp_chrome__devtools_take_snapshot`
- 如果找不到元素,先调用 `mcp_chrome__devtools_take_snapshot` 重新获取页面状态
- 每次操作失败后,都要重新获取快照再重试
### 执行原则:
- 每个操作前先观察页面状态(通过快照)
- 优先使用最可靠的元素选择器
- 遇到问题时提供清晰的错误说明
- 确保操作的准确性和完整性
请严格按照用户的步骤要求执行任务,并始终记住先获取页面快照!
"""
# 设置 MCP 客户端 - 连接到 chrome-devtools-mcp
self.client = MultiServerMCPClient({
"chrome-devtools": {
# chrome-devtools-mcp 通过 npx 直接调用,使用 stdio 传输
# --browserUrl 连接到已运行的Chrome实例,避免每次启动新的浏览器进程
"command": "npx",
"args": [
"-y",
"chrome-devtools-mcp@latest",
"--browserUrl=http://127.0.0.1:9222"
],
"transport": "stdio",
}
})
self.graph = None
self.tools = None
async def initialize(self):
"""初始化代理,获取工具并构建图"""
print("\n=== 初始化 Chrome DevTools 代理 ===")
# 获取 MCP 服务器的工具
print("正在获取 Chrome DevTools MCP 工具...")
try:
self.tools = await self.client.get_tools()
print(f"成功获取 {len(self.tools)} 个工具:")
for tool in self.tools:
print(f" - {tool.name}: {tool.description}")
except Exception as e:
print(f"获取工具失败: {e}")
print("请确保 chrome-devtools-mcp 服务器正在运行")
print("启动命令: npx -y chrome-devtools-mcp@latest")
raise
# 将工具绑定到模型
print("\n绑定工具到模型...")
self.model_with_tools = self.model.bind_tools(self.tools)
print(f"已将 {len(self.tools)} 个工具绑定到模型")
# 构建 LangGraph 工作流
self._build_graph()
print("LangGraph 工作流构建完成")
def _build_graph(self):
"""构建 LangGraph 工作流"""
# 创建工具节点
tool_node = ToolNode(self.tools)
def should_continue(state: MessagesState):
"""决定是否继续执行工具"""
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
return "tools"
return END
async def enhanced_tool_node(state: MessagesState):
"""增强的工具节点,处理快照状态管理"""
messages = state["messages"]
last_message = messages[-1]
if hasattr(last_message, 'tool_calls') and last_message.tool_calls:
print(f"\n=== 执行工具调用 ===")
# 检查是否需要先获取快照
needs_snapshot = False
for tool_call in last_message.tool_calls:
tool_name = tool_call.get('name', '')
if tool_name in ['mcp_chrome__devtools_click', 'mcp_chrome__devtools_fill',
'mcp_chrome__devtools_hover', 'mcp_chrome__devtools_drag']:
needs_snapshot = True
break
# 如果需要快照但没有先调用take_snapshot,自动添加
if needs_snapshot:
snapshot_exists = False
for msg in reversed(messages[-5:]): # 检查最近5条消息
if hasattr(msg, 'content') and msg.content and 'Page content' in str(msg.content):
snapshot_exists = True
break
if not snapshot_exists:
print("⚠️ 检测到需要快照但未找到,自动获取快照...")
# 创建快照工具调用
from langchain_core.messages import AIMessage
snapshot_call = AIMessage(
content="",
tool_calls=[{
"name": "mcp_chrome__devtools_take_snapshot",
"args": {},
"id": "auto_snapshot"
}]
)
# 先执行快照
snapshot_result = await tool_node.ainvoke({"messages": messages + [snapshot_call]})
messages.extend(snapshot_result["messages"])
# 执行原始工具调用
result = await tool_node.ainvoke(state)
return result
async def call_model(state: MessagesState):
"""调用模型"""
messages = state["messages"]
print(f"\n=== 调用模型 (消息数: {len(messages)}) ===")
if messages:
last_msg = messages[-1]
if hasattr(last_msg, 'content') and last_msg.content:
# 检查是否有工具调用错误
if "ToolException" in str(last_msg.content) or "No snapshot found" in str(last_msg.content):
print(f"⚠️ 检测到工具错误: {last_msg.content[:200]}...")
# 添加更强的错误处理指导
error_guidance = """
检测到页面快照错误!请严格按照以下步骤处理:
1. 🔍 立即调用 mcp_chrome__devtools_take_snapshot 获取当前页面快照
2. 📋 仔细分析快照内容,确认页面元素的uid
3. 🎯 使用正确的uid进行后续操作
4. ⚠️ 绝对不要在没有快照的情况下尝试点击或填充元素
记住:每次页面导航或操作后都需要重新获取快照!
"""
messages.append({"role": "system", "content": error_guidance})
else:
print(f"最新消息: {last_msg.content[:500]}...")
try:
response = await self.model_with_tools.ainvoke(messages)
if hasattr(response, 'tool_calls') and response.tool_calls:
print(f"✅ 模型请求调用 {len(response.tool_calls)} 个工具:")
for i, tool_call in enumerate(response.tool_calls):
print(f" {i+1}. {tool_call['name']}")
elif hasattr(response, 'content'):
print(f"💬 模型响应: {response.content[:500]}...")
return {"messages": [response]}
except Exception as e:
print(f"❌ 模型调用失败: {e}")
error_response = {
"role": "assistant",
"content": f"模型调用出错: {str(e)},请重试或检查配置。"
}
return {"messages": [error_response]}
# 构建图
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_node("tools", enhanced_tool_node) # 使用增强的工具节点
builder.add_edge(START, "call_model")
builder.add_conditional_edges("call_model", should_continue)
builder.add_edge("tools", "call_model")
self.graph = builder.compile()
async def execute_task(self, task_description: str):
"""执行浏览器自动化任务"""
if not self.graph:
raise RuntimeError("代理未初始化,请先调用 initialize()")
print(f"\n=== 执行任务: {task_description} ===")
try:
# 构建包含系统提示词的完整消息
messages = [
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": task_description}
]
response = await self.graph.ainvoke({
"messages": messages
})
print("\n=== 任务执行完成 ===")
# 提取最终响应
final_message = response["messages"][-1]
if hasattr(final_message, 'content'):
return final_message.content
else:
return str(final_message)
except Exception as e:
print(f"任务执行失败: {e}")
raise
async def close(self):
"""关闭客户端连接"""
# MultiServerMCPClient 不需要显式关闭
# 它会在垃圾回收时自动清理资源
pass
async def main():
"""主函数 - 演示 Chrome DevTools 自动化"""
agent = ChromeDevToolsAgent()
try:
# 初始化代理
await agent.initialize()
# 示例任务列表
tasks = [
"""
(1)打开 chrome 浏览器并导航到 https://apframework.com/
(2)理解当前页面内容,跳转到 About 页面
(3)然后翻到文章最后,获取完整的文章内容并输出
"""
]
print("\n" + "="*50)
print("Chrome DevTools 自动化任务演示")
print("="*50)
for i, task in enumerate(tasks, 1):
print(f"\n--- 任务 {i}: {task} ---")
try:
result = await agent.execute_task(task)
print(f"结果: {result}")
except Exception as e:
print(f"任务失败: {e}")
# 继续执行下一个任务
continue
# 在任务之间稍作停顿
await asyncio.sleep(1)
except Exception as e:
print(f"程序执行出错: {e}")
finally:
# 清理资源
await agent.close()
print("\n程序执行完成")
if __name__ == "__main__":
# 运行主程序
asyncio.run(main())
Chrome 持久化服务管理
在实际应用中,频繁的浏览器启动和关闭会影响性能和稳定性。为解决这一问题,我们提供了一个专业的 Chrome 持久化服务管理器:
文件:chrome_persistent_service.py
#!/usr/bin/env python3
"""
Chrome持久化服务管理器
管理独立的Chrome实例,确保浏览器在MCP调用间保持运行
"""
import subprocess
import time
import signal
import sys
import os
import requests
import json
from pathlib import Path
class ChromePersistentService:
"""Chrome持久化服务管理器"""
def __init__(self, port=9222, user_data_dir="/tmp/chrome-persistent-session"):
self.port = port
self.user_data_dir = user_data_dir
self.process = None
self.pid_file = Path("/tmp/chrome-persistent.pid")
def is_chrome_running(self):
"""检查Chrome是否在指定端口运行"""
try:
response = requests.get(f"http://127.0.0.1:{self.port}/json/version", timeout=2)
return response.status_code == 200
except:
return False
def get_chrome_info(self):
"""获取Chrome实例信息"""
try:
response = requests.get(f"http://127.0.0.1:{self.port}/json/version", timeout=2)
if response.status_code == 200:
return response.json()
except:
pass
return None
def start_chrome(self):
"""启动Chrome实例"""
if self.is_chrome_running():
print(f"✅ Chrome已在端口{self.port}运行")
return True
print(f"🚀 启动Chrome实例 (端口: {self.port})")
# Chrome启动命令
chrome_cmd = [
"/Applications/Google Chrome.app/Contents/MacOS/Google Chrome",
f"--remote-debugging-port={self.port}",
f"--user-data-dir={self.user_data_dir}",
"--no-first-run",
"--no-default-browser-check",
"--disable-background-timer-throttling",
"--disable-backgrounding-occluded-windows",
"--disable-renderer-backgrounding"
]
try:
# 启动Chrome进程
self.process = subprocess.Popen(
chrome_cmd,
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL,
preexec_fn=os.setsid # 创建新的进程组
)
# 保存PID
with open(self.pid_file, 'w') as f:
f.write(str(self.process.pid))
# 等待Chrome启动
for i in range(10):
time.sleep(1)
if self.is_chrome_running():
print(f"✅ Chrome启动成功 (PID: {self.process.pid})")
return True
print(f"⏳ 等待Chrome启动... ({i+1}/10)")
print("❌ Chrome启动超时")
return False
except Exception as e:
print(f"❌ Chrome启动失败: {e}")
return False
def stop_chrome(self):
"""停止Chrome实例"""
print("🛑 停止Chrome实例...")
# 尝试从PID文件读取进程ID
if self.pid_file.exists():
try:
with open(self.pid_file, 'r') as f:
pid = int(f.read().strip())
# 终止进程组
os.killpg(os.getpgid(pid), signal.SIGTERM)
time.sleep(2)
# 如果还在运行,强制终止
try:
os.killpg(os.getpgid(pid), signal.SIGKILL)
except:
pass
self.pid_file.unlink()
print("✅ Chrome已停止")
except Exception as e:
print(f"⚠️ 停止Chrome时出错: {e}")
# 清理进程引用
if self.process:
try:
self.process.terminate()
self.process.wait(timeout=5)
except:
try:
self.process.kill()
except:
pass
self.process = None
def restart_chrome(self):
"""重启Chrome实例"""
print("🔄 重启Chrome实例...")
self.stop_chrome()
time.sleep(2)
return self.start_chrome()
def status(self):
"""显示Chrome状态"""
print("📊 Chrome持久化服务状态")
print("=" * 40)
if self.is_chrome_running():
info = self.get_chrome_info()
print(f"✅ 状态: 运行中")
print(f"🌐 端口: {self.port}")
print(f"📁 数据目录: {self.user_data_dir}")
if info:
print(f"🔖 版本: {info.get('Browser', 'Unknown')}")
print(f"🆔 WebSocket: {info.get('webSocketDebuggerUrl', 'Unknown')}")
# 检查PID文件
if self.pid_file.exists():
with open(self.pid_file, 'r') as f:
pid = f.read().strip()
print(f"🆔 PID: {pid}")
else:
print("❌ 状态: 未运行")
print(f"🌐 端口: {self.port}")
print(f"📁 数据目录: {self.user_data_dir}")
def main():
"""主函数"""
service = ChromePersistentService()
if len(sys.argv) < 2:
print("Chrome持久化服务管理器")
print("=" * 30)
print("用法:")
print(" python chrome_persistent_service.py start # 启动Chrome")
print(" python chrome_persistent_service.py stop # 停止Chrome")
print(" python chrome_persistent_service.py restart # 重启Chrome")
print(" python chrome_persistent_service.py status # 查看状态")
return
command = sys.argv[1].lower()
if command == "start":
service.start_chrome()
elif command == "stop":
service.stop_chrome()
elif command == "restart":
service.restart_chrome()
elif command == "status":
service.status()
else:
print(f"❌ 未知命令: {command}")
print("可用命令: start, stop, restart, status")
if __name__ == "__main__":
# 处理Ctrl+C信号
def signal_handler(sig, frame):
print("\n👋 收到退出信号...")
service = ChromePersistentService()
service.stop_chrome()
sys.exit(0)
signal.signal(signal.SIGINT, signal_handler)
### 服务启动与运行
#### 启动 Chrome 持久化服务
首先启动 Chrome 持久化服务,确保浏览器实例在后台稳定运行:
```bash
python chrome_persistent_service.py start
运行 MCP 集成示例
在 Chrome 服务启动后,运行我们的 MCP 集成示例:
uv run chrome_devtools_langgraph.py
运行效果:
通过以上配置,您将看到 AI 模型通过 MCP 协议与 Chrome DevTools 进行实时交互,实现智能化的浏览器操作。整个过程展示了从自然语言指令到具体浏览器操作的完整转换链路。
3. Chrome DevTools MCP 工具参考
本节提供 Chrome DevTools MCP 服务器支持的完整 API 参考,按功能模块分类介绍各个工具的使用方法和参数说明。
3.1 输入自动化工具
点击
描述:点击提供的元素
参数:
- dblClick(布尔值)(可选):设置为 true 启用双击。默认值为 false。
- uid(字符串)(必填):页面内容快照中页面元素的 uid
拖拽
描述: 拖动将一个元素拖到另一个元素上
参数:
- from_uid(字符串)(必填):要拖动的元素的 uid(#drag)
- to_uid(字符串)(必填):要放入的元素的 uid
填充
描述: 在输入框、文本区域输入文本,或从 select 元素中选择一个选项。
参数:
- uid(字符串)(必填):页面内容快照中页面元素的 uid
- value(字符串)(必填):要填充的值(#fill)
填写表单
描述: 填写一次性填写多个表单元素
参数:
- elements (数组) (必需): 从快照到 fill 输出的元素。
处理对话框(handle_dialog)
说明: 如果打开了浏览器对话框,请使用此命令进行处理。
参数:
- 操作(枚举值:“接受”、“关闭”)(必填):是否接受或关闭对话框
- promptText(字符串)(可选):要输入到对话框中的可选提示文本。
悬停
描述: Hover 悬停在提供的元素上
参数:
- uid(字符串)(必填):页面内容快照中页面元素的 uid
按下一个键或组合键(press_key)
描述: 按下一个键或组合键。当其他输入法 fill 无法使用时(例如,键盘快捷键、导航键或特殊组合键),请使用此功能。
参数:
- 按键(字符串)(必填):一个按键或组合键(例如,“Enter”、“Ctrl+A”、“Ctrl++”、“Ctrl+Shift+R”)。修饰键:Ctrl、Shift、Alt、Meta
上传文件(upload_file)
描述: 通过提供的元素上传文件。
参数:
- filePath(字符串)(必填):要上传的文件的本地路径
- uid(字符串)(必填):文件输入元素或用于从页面内容快照在页面上打开文件选择器的元素的 uid。
3.2 导航自动化
关闭页面(close_page)
描述: 通过页面索引关闭页面。最后一个打开的页面无法关闭。
参数:
- pageIdx(数字)(必填):要关闭的页面的索引。调用
list_pages列出页面。
list_pages
描述: 获取浏览器中打开的页面列表。
参数: 无
导航页面
描述: 将当前选定的页面导航到指定的 URL。
参数:
- ignoreCache(布尔值)(可选):重新加载时是否忽略缓存。
- 超时时间(整数)(可选):最大等待时间,单位为毫秒。如果设置为 0,则使用默认超时时间。
- type (枚举: "url", "back", "forward", "reload") (可选): 通过 URL 导航页面,在历史记录中向后或向前,或重新加载。
- url(字符串)(可选):目标 URL(仅 type=url)
创建新页面(new_page)
描述: 创建新页面
参数:
- 超时时间(整数)(可选):最大等待时间,单位为毫秒。如果设置为 0,则使用默认超时时间。
- url(字符串)(必填):要在新页面中加载的 URL。
选择页面(select_page)
描述: 选择一个页面作为未来工具调用的上下文。
参数:
- pageIdx(数字)(必填):要选择的页面的索引。调用
list_pages列出页面。
等待(wait_for)
描述:等待指定的文本出现在选定的页面上。
参数:
- 文本(字符串)(必填):页面上显示的文本
- 超时时间(整数)(可选):最大等待时间,单位为毫秒。如果设置为 0,则使用默认超时时间。
3.3 模拟
模拟
描述:模拟所选页面上的各种功能。
参数:
- cpuThrottlingRate(数字)(可选):表示 CPU 降频系数。将此值设置为 1 可禁用降频。如果省略,则降频保持不变。
- networkConditions(枚举值:“无模拟”、“离线”、“慢速 3G”、“快速 3G”、“慢速 4G”、“快速 4G”)(可选):限制网络速度。设置为“无模拟”可禁用。如果省略,则网络条件保持不变。
调整窗口大小(resize_page)
描述:调整所选页面的窗口大小,使页面具有指定的尺寸。
参数:
- 高度(数字)(必填):页面高度
- 宽度(数字)(必填):页面宽度
3.4 表现
性能洞察(performance_analyze_insight)
描述:提供有关跟踪记录结果中突出显示的特定性能洞察的更详细信息。
参数:
- insightName(字符串)(必填):您要获取更多信息的洞察的名称。例如:“DocumentLatency”或“LCPBreakdown”。
性能跟踪开始(performance_start_trace)
描述: 开始对选定页面进行性能跟踪记录。这可用于查找性能问题并获取改进页面性能的见解。它还会报告页面的核心网页指标 (CWV) 得分。
参数:
- autoStop(布尔值)(必需):确定是否应自动停止跟踪记录。
- reload (boolean) (required): 确定跟踪开始后是否应自动重新加载页面。
性能跟踪停止(performance_stop_trace)
描述:停止在选定页面上进行活动性能跟踪记录。
参数: 无
3.5 网络
获取网络请求(get_network_request)
描述: 通过可选的 reqid 获取网络请求,如果省略,则返回 DevTools 网络面板中当前选定的请求。
参数:
- reqid(数字)(可选):网络请求的 reqid。如果省略,则返回 DevTools 网络面板中当前选定的请求。
列出页面所有请求list_network_requests
描述: 列出自上次导航以来对当前所选页面的所有请求。
参数:
- includePreservedRequests (boolean) (可选): 设置为 true 以返回最近 3 次导航中保留的请求。
- pageIdx(整数)(可选):要返回的页码(从 0 开始计数)。如果省略,则返回第一页。
- pageSize(整数)(可选):要返回的最大请求数。如果省略,则返回所有请求。
- resourceTypes(数组)(可选):筛选请求,仅返回指定资源类型的请求。如果省略或为空,则返回所有请求。
3.6 调试
执行 JavaScript 函数(evaluate_script)
描述: 执行当前选中页面中的 JavaScript 函数,并将响应以 JSON 格式返回。因此,返回值必须是可序列化的 JSON 格式。
参数:
- args(数组)(可选):要传递给函数的参数列表(可选)。
- function (字符串) (必填): 工具在当前选定页面中要执行的 JavaScript 函数声明。 不带参数的示例:
() => { 返回文档标题 }或async () => { 返回 await fetch("example.com") }。 带参数的示例:(el) => { 返回 el.innerText; }
获取控制台消息(get_console_message)
描述: 通过 ID 获取控制台消息。您可以通过调用 list_console_messages 获取所有消息。
参数:
- msgid(数字)(必填):页面上列出的控制台消息的 msgid
列出所有控制台消息(list_console_messages)
描述: 列出自上次导航以来当前所选页面的所有控制台消息。
参数:
- includePreservedMessages (boolean) (可选): 设置为 true 以返回最近 3 次导航中保留的消息。
- pageIdx(整数)(可选):要返回的页码(从 0 开始计数)。如果省略,则返回第一页。
- pageSize(整数)(可选):要返回的最大消息数。如果省略,则返回所有请求。
- types(数组)(可选):筛选消息,仅返回指定资源类型的消息。如果省略或为空,则返回所有消息。
截取页面或元素的屏幕截图(take_screenshot)
描述:截取页面或元素的屏幕截图。
参数:
- filePath(字符串)_(可选):保存屏幕截图的绝对路径,或相对于当前工作目录的路径,而不是将其附加到响应中。
- 格式(枚举值:"png", "jpeg", "webp") (可选):屏幕截图的保存格式类型。默认值为 "png"
- fullPage(布尔值)(可选):如果设置为 true,则会截取整个页面的屏幕截图,而不是当前可见的视口。与 uid 不兼容。
- 质量(数值)(可选):JPEG 和 WebP 格式的压缩质量(0-100)。数值越高,质量越好,但文件越大。PNG 格式不适用。
- uid(字符串)(可选):页面内容快照中某个元素的 uid。如果省略,则截取页面屏幕截图。
列出页面元素(take_snapshot)
描述: 根据 a11y 树状结构,对当前选定页面进行文本快照。快照会列出页面元素以及一个唯一的标识符。 用户标识符 (uid)。始终使用最新快照。建议优先拍摄快照而非截屏。
参数:
- filePath(字符串)_(可选):要保存快照而不是将其附加到响应的绝对路径或相对于当前工作目录的路径。
- 详细模式(布尔值)(可选):是否包含完整无障碍树中的所有可用信息。默认值为 false。
4. 总结与展望
Chrome DevTools MCP 作为一个专业的浏览器自动化解决方案,为 AI 编程助手提供了强大的 Chrome 浏览器控制能力。通过标准化的 MCP 协议,它实现了高可靠性的浏览器操作、深度性能分析和全面的调试功能。
技术优势
- 标准化集成:基于 MCP 协议的标准化实现,确保与各类 AI 编程助手的无缝集成
- 功能完整性:涵盖浏览器自动化、性能监控、网络分析、调试等全方位功能
- 生产就绪:经过实际项目验证,具备企业级应用的稳定性和可靠性
应用前景
随着 AI 编程助手在软件开发中的广泛应用,Chrome DevTools MCP 将在以下领域发挥重要作用:
- 自动化测试:为 AI 驱动的端到端测试提供可靠的浏览器控制能力
- 性能优化:通过 AI 分析实现智能化的 Web 应用性能优化
- 调试辅助:结合 AI 的智能分析能力,提升复杂问题的调试效率
Chrome DevTools MCP 代表了浏览器自动化技术与 AI 编程助手深度融合的发展方向,为现代 Web 开发提供了更加智能化和高效的工具支持。